The term "observability" has changed so many definitions through the years, especially in IT. Once, it was tied to on-site services, but now it's more related to modern cloud computing and even SaaS solutions.
So, cloud observability is one of the ways for IT teams to get insights into what's happening with systems and infrastructure. Surely, our status pages are an integral part of the observability cloud services, making it easier for organizations' IT teams to manage sudden events and handle them professionally.
Observability has become increasingly important for IT professionals as the complexity of modern systems has grown. In the past, IT environments were typically composed of a few servers and applications that were all running on-site. However, with the rise of cloud computing, IT has become more distributed, with applications and services running on a wide variety of infrastructure and platforms. This has made it harder to understand what is happening within these systems and to identify and troubleshoot issues when they arise.
One of the main challenges of observability is that it is difficult to get a complete picture of what is happening within a system. There are many different components and dependencies that can affect the performance and behavior of an application or service, and it can be difficult to understand the relationship between them. This is especially true in cloud environments, where there are often many different layers of abstractions and multiple vendors involved.
The adoption of SaaS (Software as a Service) has made observability even harder, as it adds an additional layer of complexity to the IT environment. With SaaS, organizations are relying on external providers to deliver critical business applications and services, and this can make it more difficult to understand how these systems are performing and to identify and resolve issues when they arise.
To address these challenges, many cloud providers now offer public status pages that provide information about the availability and performance of their services. These status pages provide IT professionals with real-time status updates on the services they rely on. However, managing multiple status pages can be time-consuming and cumbersome, and it can be difficult to get a comprehensive view of the overall health of an IT environment.
A service like StatusCast that aggregates SaaS status pages into a single, real-time notification service for IT teams is a valuable tool for improving observability and reducing the burden on IT professionals. By providing a single source of truth for the status of all the SaaS services an organization relies on, such a service can help IT teams to more easily monitor the health of their systems and to identify and resolve issues more quickly. In addition, this type of service can help to automate the observability process, freeing up IT professionals to focus on more strategic tasks.
Observability is critical for modern IT environments, but it can be challenging due to the complexity of modern systems and the adoption of SaaS. Public status pages offered by cloud providers can be helpful, but a service that aggregates these pages into a single, real-time notification service is even more valuable, helping IT teams more easily monitor the health of their systems, identify issues and resolve incidents more rapidly.
The Incident Management and Status Page solution that lets you organize your enterprise IT team and communicate with users for a coordinated response that restores services rapidly.
______________________________________________________________________
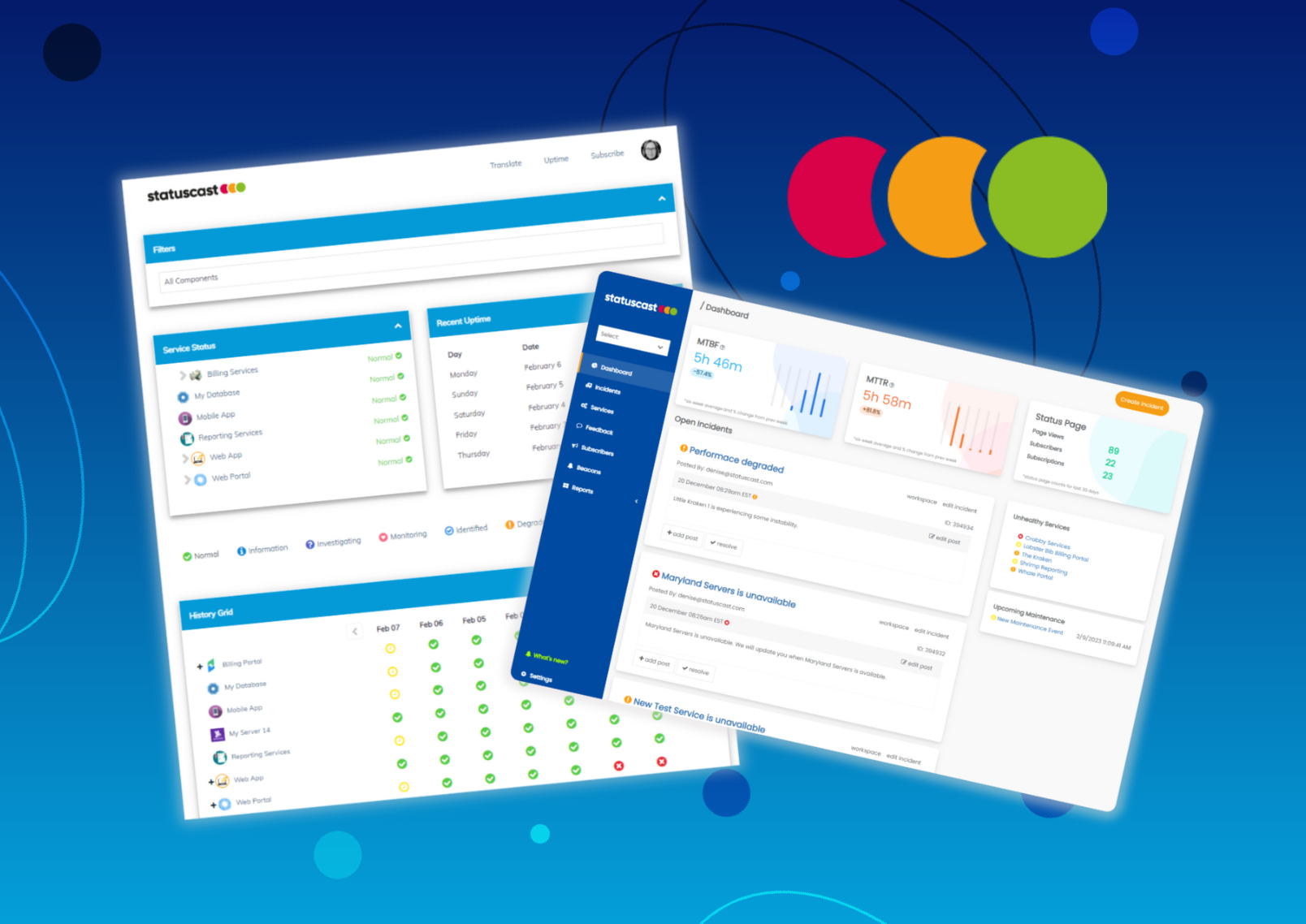
StatusCast works as an Incident Management platform to increase employee productivity inside organizations. There's a lot you can do with StatusCast status pages to create the brand look you are seeking.
When a system is experiencing an outage or a performance issue, keep your end users informed on its status by using incident updates. As you get more information about service issues, be proactive in keeping your end users in the loop with the latest info and expected recovery time.
Using our user-friendly analysis to examine settled incidents to gain an understanding of how this issue began in the first place, and how well the accomplished exercise went and what, if anything, could have been done preferable the next time.
Our Analytics dashboard provides a quick and easy way to see what areas of your network will need more immediate repair, allowing you to drive toward true dependable fixes.
The true power of incidents is what you learn from them and how you recycle those learnings back into your system. But the barrier to entry for learning from incidents through retrospectives is still too high. For many companies, the process is different each time, it’s cumbersome to gather data, and it’s really challenging to look at multiple retros and find trends. We want to make it so simple, predictable, and consistent for you to run retros that you run them for every incident. Today’s release brings that possibility to light.
Keeping stakeholders and customers informed during an incident builds trust and creates an atmosphere of patience. If trained correctly, status pages are often the initial location where internal and external users go for information, so it’s vastly important that your users are receiving real time information.
Improving the communication based around changes to your internal ITSM solution provides you with increased awareness and employee productivity while the IT division is troubleshooting problems privately or publicly. Now, whenever an incident is seemingly forthcoming, those influential key people who need to be notified are automatically informed in advance.
See how easy it is to become the champion of the company Book A Demo
As digital services have become increasingly important to businesses and organizations, reducing downtimes and service disruptions have become critical objectives for business operations. This means management reporting and KPI's are now crucial to quality management, providing the insight to let you improve incident remediation over time.
Tracking incident management metrics means you can utilize the data available to set benchmarks and goals, measure and reduce incident impact, and identify and anticipate recurring service problems.
But what metrics and incident management KPIs to track? How to ensure you won't get bogged down with too many incident response metrics and analysis data?
Here are a few things to know about it:
Key performance indicators (KPIs) are data points that teams use to monitor the performance of their systems and personnel performance. By tracking these different metrics in the short, medium, and long term, you'll be able to see if your goals and timelines are being met. Of course, given the scale and complexity of today's tech infrastructures, this is no easy task, so tools that can gather this data for you in an easy-to-understand way are essential for most organizations. Once you have the right tools to do this, the next step is to decide on the metrics and KPIs important to your organization.
When considering which metrics to track, it may seem like measuring as much as possible will be the best way to ensure you get all the information you need. And while incident management software can capture vast amounts of data, analyzing it all can be far too time-consuming and obscure issues rather than clarify them.
So, what are some of the metrics you should be keeping a close eye on?
If you're using an alerting tool, it's helpful to know how many alerts are generated in a specific period, whether a week, a month, or longer. Analyzing this over time will give you a baseline of how busy the team is and help to identify periods with significant increases or decreases or notable changes over a longer period. Once you spot a trend, you can dig deeper and try to find out why those changes are happening and how your teams are addressing them.
MTBF (Mean Time Between Failures) is the average time between repairable product or tool failures. This incident management KPI helps you track availability and reliability across assets. By analyzing it, you can set incident response metrics and measure if systems are failing more often than expected, so you can assign a resource to reduce or prevent it.
Tracking incidents over time means looking at the average number of incidents in a given period, whether weekly, monthly, quarterly, yearly or even daily. Look at whether incidents are happening more or less frequently over time and if the number of incidents is at an acceptable level or whether it needs to be reduced. If you identify a problem with the number of incidents being reported, you can start to ask questions about why that number is trending upward or staying high and what the team can do to resolve the issue.
Having made promises in service level agreements, such as uptime and response times, you must be aware of any breaches or issues that were slow to resolve. SLA compliance rate should be constantly monitored and updated to accurately reflect your service's current state. So, setting problem management SLA metrics and KPIs will significantly enhance your efficiency when dealing with SLA compliances.
Measuring this will tell you if your resolution times are as they should be and how quickly your team can get the right person working on an incident. If times are higher than expected, it's time to delve deeper into why and examine how issues are communicated.
Mean time to repair, resolve, respond, or recovery is a key metric that tracks the time spent diagnosing and fixing a problem and ensuring it doesn't happen again. It will show how long, on average, it takes to respond to and resolve an incident.
While metrics that show how you're responding to incidents are crucial, it's also worth measuring the percentage of time your systems are actually up and fully functioning. The industry standard is 99.9% uptime is very good, and 99.99% is excellent. If you're currently below this, use the data available and work with your team to find out why – chances are there are multiple reasons, not one quick fix.
This will show you how incidents are resolved during the first occurrence with no repeat alerts. By keeping an eye on this over time, you'll be able to see how effective your incident management processes become – a high rate of first-time fixes suggests your systems are working well.
Having made promises in service level agreements, such as uptime and response times, you must be aware of any breaches or issues that were slow to resolve. SLA compliance rate should be constantly monitored and updated to accurately reflect your service's current state.
By tracking how much it costs to resolve each incident, you can determine which methods are most effective in terms of time and money spent, thus boosting efficiencies in the long run.
Other metrics worth tracking include incident backlog, the number of pending incidents in the queue without a resolution, and the percentage of major incidents, that is how many incidents are deemed major compared to the total number reported. These can both help you to get a thorough understanding of the situation and how effectively incidents are being managed.
Giving your team clear KPIs for incident management and realistic goals is a great way to ensure their performance matches the broader organizational goals of minimal disruption and maximum uptime. If the metrics are continuously missed, it's vital to reassess rather than keep enforcing the same targets. For example, if average incident response time is consistently higher than the target, you need to find out why. Are the systems in place insufficient, are your alerts set up most effectively, or is there a deficiency in the team setup or skillset? Delving into the data will help you reveal the root cause so you can make the necessary changes.
While having access to all this data is invaluable, it's also essential to consider the human element of incident management. For example, while you can see from your KPIs that incidents are taking longer to fix, you won't be able to see if the complexity of incidents is increasing or the risks associated with them are higher, or the unexpected elements are more significant, and so on. Combining data with input from the team will help you make significant improvements that will last.
StatusCast offers a great starting point for this insight with its Task Reporting. This enables you to measure how effective individuals and teams are at remediation when performing the specific tasks assigned to them, creating the opportunity to identify bottlenecks in the incident management process relative to task assignment.
Another metric to consider here is on-call time. If you have an on-call rotation, tracking how much time employees and contractors spend on call can be worthwhile to ensure team members aren't overburdened. An incident management solution that helps you manage your IT team and organize shift working and on-call support can be invaluable here.
To make sure you're able to access the data that matters to you quickly and in a format that makes sense, the right incident management software is essential. With StatusCast, you'll have access to clear, accurate information via intuitive dashboards that give you the necessary information. Incident reporting provides a detailed analysis of past incidents to measure team efficiency and resolution time and identify IT assets prone to problems. You can also automatically keep track of the operational uptime for all your corporate assets or across every individual component and service. StatusCast also provides a fully auditable record of every notification sent to your team, employees, customers, and partners. With StatusCast notification reporting, you get traceability of the communication history of each incident so you can be clear on how your team is responding.
These are just a few ways StatusCast can help you monitor and measure your incident management response to ensure rapid responses and successful resolutions now and in the longer term.
Book a demo now or start your free trial to find out more.
Good communication is at the core of any incident management process, empowering stakeholders with the information they need to avoid lost productivity. Delivering the right message through the right channel to the right people across the enterprise is key - if you’re simply firefighting and communicating reactively, stakeholders will likely get frustrated.
Having a set of procedures and actions to identify and resolve incidents is crucial to ensure that issues are addressed quickly, efficiently, and with minimum impact on users. An effective incident management cycle will cover every aspect of the resolution process, from how incidents are detected to the tools available to fix them, and resolution and recovery, and it’ll enable clear and accurate communication with stakeholders at every stage.
So how can you ensure your incident management process is effective, recurring problems can be identified and uptime improved? The first step is to understand each stage of the incident management lifecycle and put processes in place to address each one appropriately.
It’s estimated that Fortune 1000 organizations lose between $1.25bn and $2.25bn a year in application downtime. That may be due to service downtime, regulatory fines, or loss of customers due to dissatisfaction with the service. With numbers like this, it’s clear why incident management is important.
By taking effective incident management steps, IT teams can quickly address any vulnerabilities and issues. That way, they manage to reduce their impact, getting systems and services up and running more quickly - all while communicating effortlessly with stakeholders.
Without these processes, organizations will suffer not just from lost revenues but reduced productivity and potential data loss and could be in breach of service level agreements. This will inevitably lead to unhappy customers and stakeholders, and could impact reputations, with organizations being seen as poor service providers.
It is generally agreed that there are six stages of incident management.
Several tools will help you to identify an incident. This could be through user reports, solution analysis, or even manual identification. The aim will be for issues to be detected before they impact users so you can communicate the problem and advise on resolution times, but this may not always be possible. Either way, the incident must be logged to take the necessary actions. And crucially, even if you’re not sure of the extent of the problem, inform users straight away of an issue under investigation.
The first action will be to categorize the incident so it can be prioritized and escalated as needed. Whether it’s business critical or a minor inconvenience to a few users will determine the initial response and how much resource needs to be allocated.
In this crucial step, tasks will be assigned, and the process of investigating the incident can begin in earnest. The type and cause of the incident, along with the extent of the compromise, will be the initial areas of focus, and any additional resources needed can be identified and brought into the loop.
The assigned team can now begin the vital work of investigating the type, cause, and possible solutions for the incident.
It’s essential to ensure any affected stakeholders, such as staff and customers, are informed about the incident and any disruption of services. In fact, communication can be underrated and even overlooked as teams try to solve issues, but it’s important that any incident management process enables quick, easy and accurate messaging at all times.
Resolution occurs when the initial threat or root causes have been eliminated, systems restored to full function, and the business impact has ended. Closing incidents typically involves finalizing documentation and evaluating the steps taken during the response to see if there are any areas of improvement. You may also be required to write up a report of the incident to deliver to management so they can be clear on both the situation and the response to it.
While the initial impact on the business may have passed, that doesn’t mean an end to the situation. Effective incident management will also include root cause analysis so that you don’t just understand why the incident occurred; you can learn from any underlying issues and use this information to avoid similar problems in the future. Although often overlooked, RCA is key to longer-term improvements in performance. If you have a robust incident management system, you’ll be able to access crucial incident data after the event, which you can use to build up this resilience. With StatusCast, for example, you’ll be able to build a root cause analysis library that lets you track why incidents continue to happen, identify common issues, and plan preventative maintenance to help to avoid them.
Following these steps and having suitable systems in place will inevitably help ensure a swift response to any issues. Still, other steps can be taken to deliver smooth and streamlined answers whatever the situation.
Among these is ensuring employees across the organization have the training, support, tools, and knowledge they need to identify, report and resolve issues. Crucially, this shouldn’t just be IT, staff. All employees should know how to correctly report an issue so that the relevant people can begin the job of fixing it. Of course, the better trained your IT team are, and the better they work together, the more likely issues will be resolved in good time.
The key to this is also the right platforms to ensure issues can be reported and responses optimized for better outcomes. Look for tools that offer automated alerts, ease of escalation, and simple collaboration between team members.
While automated alerts are hugely valuable, it’s crucial to avoid alert overload. If too many alerts are coming in, the team won’t be able to action them all, and response times will suffer, leading to dissatisfaction among stakeholders. To avoid this, take the time to plan how events are categorized and what those categories mean for alerts. Perhaps begin by defining your service level indicators and use these to prioritize root causes rather than surface-level symptoms.
Clear, timely communication will be central to how well incidents are responded to. Essential steps to achieve this include having an on-call schedule so someone with the necessary skills and permissions will always be available to respond to an incident. Setting this schedule shouldn’t be a one-off project, so be sure to revisit it regularly to ensure you’re not overly reliant on any one individual. If you are, this could suggest a skills shortage that needs addressing.
Creating guidelines that specify what channels staff should use to communicate, how communications should be documented, and how to share different files and content will also help things to run more smoothly during stressful situations. Clear documentation will also enable teams to verify information quickly and make any necessary checks.
That documentation can also be valuable for those all-important post-incident reviews. These should be a central part of any incident management process as not only can they highlight any preventative maintenance issues that need to be carried out, they can also identify any areas of the response that need reviewing. This is also a good time to ensure all documentation has been completed correctly should there be any liability and compliance auditing.
With StatusCast, teams can achieve faster incident resolution through an organized, collaborative response that means the right people are informed promptly of an issue, and, crucially, they can access the information they need to diagnose and resolve that problem quickly. If systems fail or go offline, a simple to use platform that manages every aspect of the incident throughout its lifecycle is key to resolving disruptions and minimizing downtimes. StatusCast offers all this and more. From streamlined incident reporting through to automatic team assignments and integration with third-party monitoring services as well as Slack and MS Teams, StatusCast can help to reduce business impacts, identify patterns and enhance response processes, all of which will minimize downtimes, improve the bottom line and lead to more satisfied users.
To find out more, book a demo now or start your free trial.
What’s just as important as resolving an impacted service? Providing detailed yet digestible updates to your communities and stakeholders. A recent update to StatusCast, involves the addition of three new status types that can be assigned to your components. Detailed communications is an essential component of incident response and management, and additional status types provide your users with a more granular view of incident activity. So whether you are building trust amongst customers by taking a more transparent approach, or communicating your troubleshooting process internally, having concise and varied statuses at your disposal ultimately equals a better informed community.
Incident Response Timeline
From the moment your component is impacted, accurately labeling each stage, from identification to restoration allows your team to better track the troubleshooting process. We call this the Incident Response Timeline. Is there a pattern you are noticing surrounding the time it takes to identify the root cause of an issue? What’s the average amount of time your team takes to monitor an issue before reverting to an all clear? Integrating more detailed statuses can continue to help you assess the effectiveness of your incident response and even provide your subscribers and viewers a better look into what’s affecting them.
On all Incident Management admin and status pages, the following new statuses: Investigating, Monitoring, and Identified will be available for use. Take a look at how they will appear in the Table of Contents on a Status Page.

Like all of our statuses, the descriptions are fully customizable to adhere to your company’s terminology.
Customization and Localization
In the Administration Page, Navigate to Settings and then Localization and finally Status Text. In this window, you will be able to change the text of the several different statuses available.

If you have any questions or suggestions about any StatusCast feature, please get in touch, or to try this out, sign up for a trial here.
Here at StatusCast we understand the importance of a resourceful and communicative status page. A status page is the ambassador of your incident response management process, and like any good ambassador, it needs to speak the language. If your status page is now hosted by StatusCast, it is now fully integrated with Google Translate, a powerful tool that allows your subscribers and even viewers to translate your page into the language most comfortable to them. This means nothing gets lost in translation, which is critical when dealing with incident investigation and resolution. Currently, Google Translate includes 132 languages and is included on all status pages for free.
![]()
How does it look?
Come check it out on our very own status page at StatusCast. After selecting a language, the page is translated from English:
![]()
To for example, Latvian:
![]()
How do I set it up?
Each page comes equipped with a Page Designer which allows you to customize all the widgets on your page. A new checkbox appears in the Header widget that allows you to show the Google Translate. Step-by-step instructions can be found here, Enabling Google Translate.
Enabling Google Translate on your page to allow for your subscribers to see all incident posts, and even the calendar all in the language of their choice.
To understand the impact that stovepipes have on incident response, one need look no further than the 9/11 terrorist attacks that occurred in the United States. The CIA, DoD, and FBI all knew about the Al Qaeda terror threats before the planes hit the World Trade Center, but the 9/11 Commission found that a lack of data and intelligence sharing among the agencies limited each agency’s understanding of the looming terrorist threat; thereby, limiting their incident response. This lack of information sharing made it difficult for intelligence leaders to "connect the dots" and thwart the attack.
Thankfully, most IT stovepipe scenarios do not lead to such dire consequences; however, they do impact incident response when your IT systems go down. Wikipedia defines IT stovepipes as "systems procured and developed to solve a specific problem, characterized by a limited focus and functionality, and containing data that cannot be easily shared with other systems."
These singularly focused, non-integrated systems make the lives of IT help desk support personnel more time-consuming, more expensive and more frustrating (for both the support team and business stakeholders outside of the IT organization).
Employees and customers increasingly demand more transparency from corporate IT support teams, making stovepiped systems an "ugly" word with IT leaders. One of the best ways to meet the demand for more transparency is to invest in a Corporate Status Page.
A corporate Status Page provides a unified portal from which your IT help desk staff can assess all problems and planned outages across your IT ecosystem. Having a unified view provides your IT help desk team with holistic insight into the status of your enterprise IT systems & software. This all-encompassing perspective is invaluable when communicating with employees and customers about outages and planned maintenance.
By providing proactive incident management and planned maintenance communications, a corporate Status Page helps boost stakeholder trust, which in-turn leads to better customer and employee satisfaction.
In addition, by having all IT notifications feed into a single Status Page, you boost your IT help desk team’s productivity and reduce your IT support costs.
When looking to bust your incident response silos, you must ensure the Status Page solution you select meets the following requirements:
Allows for end-user-friendly, customizable pages and messages to provide stakeholders information they can use and understand versus "tech-speak"
If your business is plagued by silos in your IT incident management approach, you should consider a corporate Status Page. You’ll not only boost IT help desk team productivity, but also you’ll improve IT transparency, which has been proven to improve both employee and customer satisfaction.
© Copyright StatusCast 2022 | Terms & Conditions | Privacy Policy