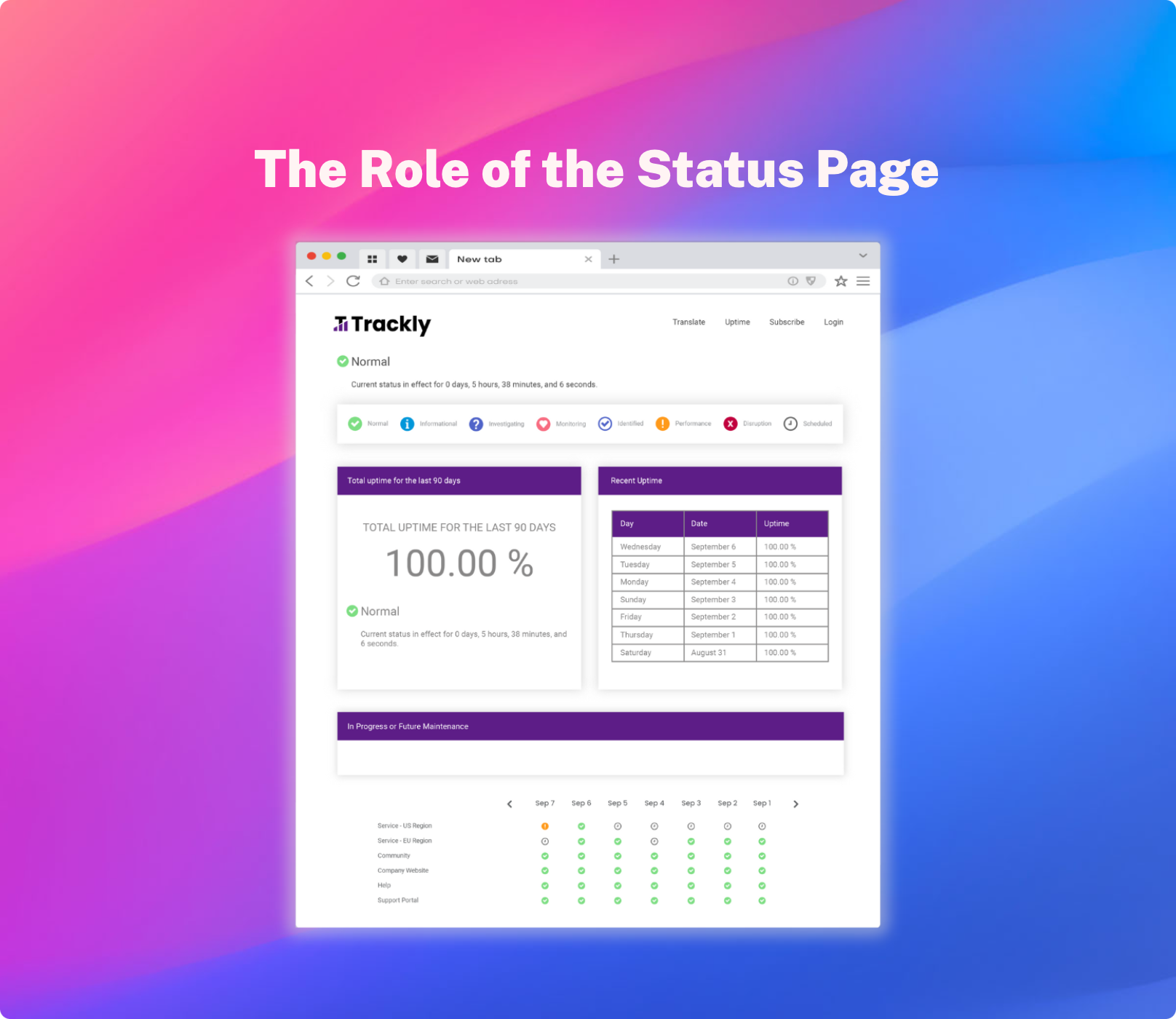


Good communication is at the core of any incident management process, empowering stakeholders with the information they need to avoid lost productivity. Delivering the right message through the right channel to the right people across the enterprise is key - if you’re simply firefighting and communicating reactively, stakeholders will likely get frustrated.
Having a set of procedures and actions to identify and resolve incidents is crucial to ensure that issues are addressed quickly, efficiently, and with minimum impact on users. An effective incident management cycle will cover every aspect of the resolution process, from how incidents are detected to the tools available to fix them, and resolution and recovery, and it’ll enable clear and accurate communication with stakeholders at every stage.
So how can you ensure your incident management process is effective, recurring problems can be identified and uptime improved? The first step is to understand each stage of the incident management lifecycle and put processes in place to address each one appropriately.
The importance of incident management
It’s estimated that Fortune 1000 organizations lose between $1.25bn and $2.25bn a year in application downtime. That may be due to service downtime, regulatory fines, or loss of customers due to dissatisfaction with the service. With numbers like this, it’s clear why incident management is important.
By taking effective incident management steps, IT teams can quickly address any vulnerabilities and issues. That way, they manage to reduce their impact, getting systems and services up and running more quickly - all while communicating effortlessly with stakeholders.
Without these processes, organizations will suffer not just from lost revenues but reduced productivity and potential data loss and could be in breach of service level agreements. This will inevitably lead to unhappy customers and stakeholders, and could impact reputations, with organizations being seen as poor service providers.
What are the stages of incident management?
It is generally agreed that there are six stages of incident management.
Detection and logging
Several tools will help you to identify an incident. This could be through user reports, solution analysis, or even manual identification. The aim will be for issues to be detected before they impact users so you can communicate the problem and advise on resolution times, but this may not always be possible. Either way, the incident must be logged to take the necessary actions. And crucially, even if you’re not sure of the extent of the problem, inform users straight away of an issue under investigation.
Categorize, prioritize and assign
The first action will be to categorize the incident so it can be prioritized and escalated as needed. Whether it’s business critical or a minor inconvenience to a few users will determine the initial response and how much resource needs to be allocated.
In this crucial step, tasks will be assigned, and the process of investigating the incident can begin in earnest. The type and cause of the incident, along with the extent of the compromise, will be the initial areas of focus, and any additional resources needed can be identified and brought into the loop.
Analyze
The assigned team can now begin the vital work of investigating the type, cause, and possible solutions for the incident.
Communicate the problem
It’s essential to ensure any affected stakeholders, such as staff and customers, are informed about the incident and any disruption of services. In fact, communication can be underrated and even overlooked as teams try to solve issues, but it’s important that any incident management process enables quick, easy and accurate messaging at all times.
Resolution
Resolution occurs when the initial threat or root causes have been eliminated, systems restored to full function, and the business impact has ended. Closing incidents typically involves finalizing documentation and evaluating the steps taken during the response to see if there are any areas of improvement. You may also be required to write up a report of the incident to deliver to management so they can be clear on both the situation and the response to it.
Root cause analysis
While the initial impact on the business may have passed, that doesn’t mean an end to the situation. Effective incident management will also include root cause analysis so that you don’t just understand why the incident occurred; you can learn from any underlying issues and use this information to avoid similar problems in the future. Although often overlooked, RCA is key to longer-term improvements in performance. If you have a robust incident management system, you’ll be able to access crucial incident data after the event, which you can use to build up this resilience. With StatusCast, for example, you’ll be able to build a root cause analysis library that lets you track why incidents continue to happen, identify common issues, and plan preventative maintenance to help to avoid them.
How to improve your Incident Management Processes
Following these steps and having suitable systems in place will inevitably help ensure a swift response to any issues. Still, other steps can be taken to deliver smooth and streamlined answers whatever the situation.
Among these is ensuring employees across the organization have the training, support, tools, and knowledge they need to identify, report and resolve issues. Crucially, this shouldn’t just be IT, staff. All employees should know how to correctly report an issue so that the relevant people can begin the job of fixing it. Of course, the better trained your IT team are, and the better they work together, the more likely issues will be resolved in good time.
The key to this is also the right platforms to ensure issues can be reported and responses optimized for better outcomes. Look for tools that offer automated alerts, ease of escalation, and simple collaboration between team members.
While automated alerts are hugely valuable, it’s crucial to avoid alert overload. If too many alerts are coming in, the team won’t be able to action them all, and response times will suffer, leading to dissatisfaction among stakeholders. To avoid this, take the time to plan how events are categorized and what those categories mean for alerts. Perhaps begin by defining your service level indicators and use these to prioritize root causes rather than surface-level symptoms.
Clear, timely communication will be central to how well incidents are responded to. Essential steps to achieve this include having an on-call schedule so someone with the necessary skills and permissions will always be available to respond to an incident. Setting this schedule shouldn’t be a one-off project, so be sure to revisit it regularly to ensure you’re not overly reliant on any one individual. If you are, this could suggest a skills shortage that needs addressing.
Creating guidelines that specify what channels staff should use to communicate, how communications should be documented, and how to share different files and content will also help things to run more smoothly during stressful situations. Clear documentation will also enable teams to verify information quickly and make any necessary checks.
That documentation can also be valuable for those all-important post-incident reviews. These should be a central part of any incident management process as not only can they highlight any preventative maintenance issues that need to be carried out, they can also identify any areas of the response that need reviewing. This is also a good time to ensure all documentation has been completed correctly should there be any liability and compliance auditing.
StatusCast Incident Management
With StatusCast, teams can achieve faster incident resolution through an organized, collaborative response that means the right people are informed promptly of an issue, and, crucially, they can access the information they need to diagnose and resolve that problem quickly. If systems fail or go offline, a simple to use platform that manages every aspect of the incident throughout its lifecycle is key to resolving disruptions and minimizing downtimes. StatusCast offers all this and more. From streamlined incident reporting through to automatic team assignments and integration with third-party monitoring services as well as Slack and MS Teams, StatusCast can help to reduce business impacts, identify patterns and enhance response processes, all of which will minimize downtimes, improve the bottom line and lead to more satisfied users.
To find out more, book a demo now or start your free trial.