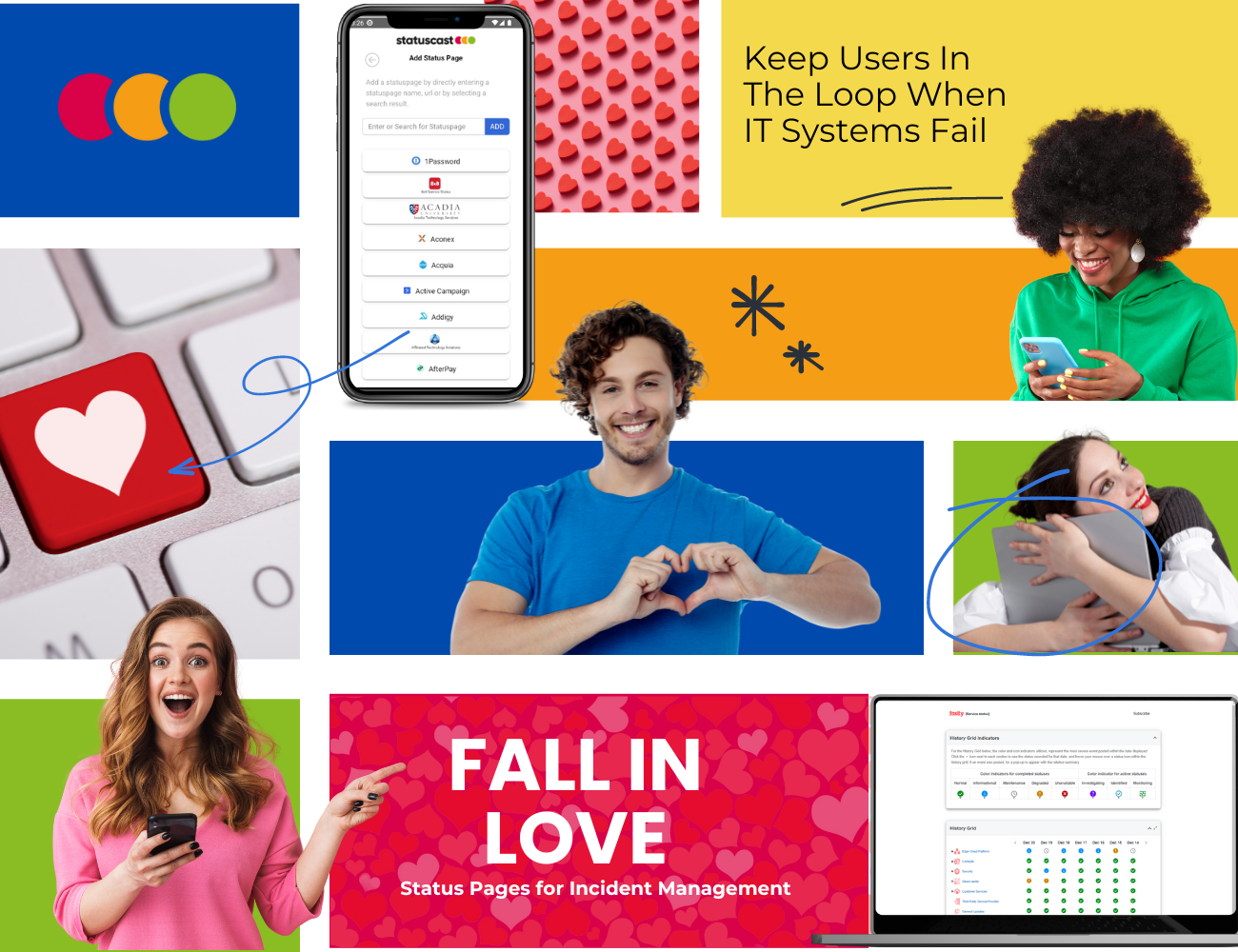
In the modern day IT landscape, service reliability is of the utmost importance. Status pages serve as crucial interfaces, communicating any interruptions or issues to stakeholders. While several options are available, two notable status page providers stand out: StatusCast and Status.Io. Here we take a dive into the various aspects of status pages and incident management for each status page service.
Status Page Types
Status.io and StatusCast both offer Public and Private Status Pages. However, while Status.io is positioned to provide for small to mid market customers who need a basic status page to report on a simple IT infrastructure, StatusCast is built to meet the needs of enterprises. Thereby providing a best-in-class private status page built for effective internal incident communication for large organizations managing a myriad of complex systems and organizational structure. StatusCast goes beyond a simple dashboard to monitor downtime, to a scalpel that cuts to the heart of downtime costs, reducing employee productivity loss and empowering IT to expedite incident resolution. StatusCast’s first class experience goes a step further, with Audience Specific Pages, which are custom status page views for end users based on their roles or needs, providing updates and visibility only about components and services that affect them.
Incident Management and Reporting
While the status page is Status.io's only product line, StatusCast also offers an end to end Incident Management suite that IT departments can leverage to coordinate efforts and manage processes to accelerate incident resolution. StatusCast’s Incident Management solution can be utilized as a stand alone, or combined with any status page. Their incident management offers many cutting edge features that equip IT to manage downtime effectively, including its Root Cause Analysis (RCA) Reporting, allowing teams to not just respond but to proactively understand and address the origins of disruptions before they occur. Their incident management service also provides intelligent escalations, automating incident response by notifying the right people. The pairing of incident management software combined with a status pages ensures that incidents aren't just effectively communicated, but are proactively managed with enhanced foresight and efficiency.
Subscriber Controls
Both StatusCast and Status.Io offer extensive subscriber notifications. However, StatusCast elevates the personalized experience for subscribers to a new level with the enhanced segmentation of their audience-specific status pages, delivering tailored notifications about relevant component or service statuses. By only delivering information pertinent to each subscriber, StatusCast effectively eliminates unnecessary noise and alert fatigue.
Third-Party Status Page Integrations
Status.io and StatusCast both provide third-party status page integrations, but StatusCast offers many of these integrations out of the box. Where StatusCast truly differentiates itself is in the granularity of its integrations. With StatusCast, users can selectively integrate specific components or services from third-party pages. This ensures that businesses present only the most relevant information to their users, ensuring a streamlined experience. This level of detail and precision, paired with out-of-the-box availability, sets StatusCast ahead with regard to third-party status page integrations.
Status page customization
While both Status.io and StatusCast support the fine-tuning abilities provided by custom CSS, StatusCast goes a step further in supporting a tailor made status page experience. StatusCast provides an intuitive drag-and-drop status page builder enabling those with limited technical expertise, or with limited time, to craft and mold their status page to meet the standards of their brand design and user experience. When it comes to status page notifications, StatusCast’s customizable email templates communicate brand trust that end-users expect. From the website to the inbox, the message remains consistently 'yours'. StatusCast also enables custom content like widgets or buttons, provides over 20 widgets with granular controls over their data and visibility, and supports single or multi-column layouts.
While Status.io positions itself as a provider for small to mid market buyers who need a basic status page solution, StatusCast's SMB plan for 2,000 status page subscribers actually comes in at a lower price point than Status.io's Standard plan offering the same number of subscribers. StatusCast’s ITSM services are built for enterprises, but with competitive pricing that scales relative to the needs of customers of any size.

The reliability and responsiveness of a status page are paramount, as the status page is the the first line of defense during IT failures. When evaluating performance, key metrics to consider include uptime, latency, and the agility of alert notifications. Both StatusCast and Status.io consistently deliver in these areas, ensuring reliable performance of their status page functionality during critical incidents.
Both StatusCast and Status.io excel in user-friendliness, setting them apart from other status page services. Their easy setup and intuitive configuration streamline the onboarding process. StatusCast's dashboard is designed with the convenience of set-up in mind, providing full control over the selection and drag-and-drop functionality of various types of widgets. Both platforms offer support, but StatusCast’s extensive online guides in their knowledgebase go further to give users in-depth information, ensuring they get the most out of the platform.
StatusCast stands apart as a holistic solution, offering not only status page software but also an all-encompassing incident management suite. This proves to be the starkest contrast between Status.io and StatusCast, as Status.io only provides a status page. What sets StatusCast's incident management solution apart from others is its unique position to leverage a status page that prioritizes stakeholder communication and takes an asset first approach to managing incidents. This strategic design empowers businesses to effectively diminish the economic impact of service outages. The emphasis on reducing mean time to resolution (MTTR) and minimizing employee productivity loss makes it uniquely positioned to significantly reduce the cost of downtime.
StatusCast’s Incident Management Features Include:
In the quest for a reliable status page provider, a vendor's reputation stands as a testament to their capability in staving off IT failures that cascade into immense financial and reputational costs. StatusCast maintains some of the highest ratings of any status page service on platforms like G2 (4.8/5) and Capterra (4.8/5), whereas any reviews for Status.io are difficult to find.
While both platforms have their merits, your choice will hinge on your specific needs. If you value a robust solution to incident communication, with superior integrations and customization, and comprehensive incident management, that is trusted by some of the largest Fortune 100 enterprises, then StatusCast is the obvious choice. However, for businesses on a tighter budget who are looking for a basic solution, Status.Io might suffice.
StatusCast offers 3 status page types based on the specific needs of the customer, while Status.io only offers 2. Also, StatusCast offers an entire incident management product that Status.io does not.
Both aim for high reliability, but StatusCast's advanced monitoring offers quick notifications during interruptions. StatusCast has been a profitable and self-funded company, trusted by some of the world's largest enterprises across healthcare, telecommunications and SaaS since 2013.
Someone in the market for a status page solution should consider: reputation and longevity, proactive multi-channel notifications, status page types, customization, integration capabilities, incident management features, and pricing.
StatusCast is the entire package for enterprise businesses to proactively manage incidents, reduce lost employee productivity during outages and mitigate the cost of downtime by keeping your employees and your customers informed during service outages.
Maintaining a comprehensive and engaging status page is the cornerstone of an effective incident communication strategy, yet too many companies limit themselves in this respect. Some rely on an assortment of disjointed application monitoring and manual incident notifications, while others look to the cheapest status page they can find. For any organization that wants to reduce the severe costs of downtime or provide a first rate experience to users, a centralized status page, with unmatched capacity and customization is the answer. The ability to be in full control of the design of your status page and all your incident notifications is key to deliver the best experience to your customers.
Learn what Limitless Customization can do for your Status Page
View Our Webinar
Customization isn't just about putting a distinctive stamp on your status page or your email notifications—it's about ensuring the platform seamlessly caters to your users' needs. From enterprises that want to craft every pixel to perfection, to startups seeking an easy out-of-the-box solution, the ability to adapt your status page to your unique requirements is what makes it a truly effective communication tool. StatusCast is built to support both visions, facilitating a bespoke status page experience, delivering a status page consistent with your brand that resonates with your users.
For those seeking to maximize their design potential, StatusCast understands that the scope of customization goes even beyond the status page itself. Often, the ideal user experience is one that doesn’t even reach the status page, but instead, simply ensures that any users affected by an incident are notified and kept in the loop. Unlike any other status page, with StatusCast you can craft fully customizable email templates, from the appearance and design to the layout and formatting, you have full control over how your notifications represent your brand and serve your customers. The ability to control the content, layout and aesthetics of your notifications means that you can provide critical updates in a manner that is not just informative, but also carries the trust and appeal of your brand.
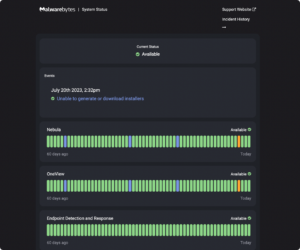
Our status pages also offer the unique ability to control visibility of widgets and important data on your status page. This enables you to tailor the data presented to various audiences, thereby enhancing the relevance and user-friendliness of your status page. Want to explore the design space even further, utilizing custom CSS to maximize the aesthetic appeal of your status page? See how Malwarebytes leveraged custom CSS that triggered the user’s Windows dark/light mode to create a sleek and minimalist page design.
For those who appreciate design but might lack the time or resources to fully commit to it, we offer an arsenal of pre-made status page themes and styling, allowing you to quickly launch a page that's not just functional, but also polished and presentable. Our drag-and-drop page builder is an intuitive tool that makes it easy to design a status page without needing waste precious time getting stuck in the design stage. Our pages support single and multi-column designs, with over 20 widgets whose layout and appearance you have full control over. The ability to control the layout of widgets on your status page and easily decide what content is displayed ensures that you can rapidly launch an effective and visually appealing status page.
It's clear that the power of customization is multi-faceted, catering to a wide spectrum of needs and preferences. From full design authority to user-friendly design tools, customization ensures your status page is not just another communication tool, but a strategic asset that can enhance your brand, streamline user experience, and ultimately, drive customer satisfaction.
At StatusCast, we invite you to check out our previous webinar on Status Page Customization, where we delve deeper into how our customization features can take your status page UX to the next level.
Incident Management and Problem Management are two concepts that take an integral part of the IT service management, or shortly, ITSM. Even though they seem similar, and many will use the terms incorrectly, they have different purposes.
This blog post will help you understand the differences between Incident Management vs Problem Management. As a result, you will learn how to apply these concepts in your own approach to handle incident management.
Before we explain the difference between incident and problem management, we must define the terminology to understand each term easily and what it refers to.
Shortly, incident management deals with issues that come up suddenly, while problem management focuses on the root causes behind those incidents.
But let's explain these terms before diving deeper into the topic.
Incident Management is the process of addressing and resolving unplanned events or interruptions affecting the quality of an IT service. The primary goal is to regain normal service operations and minimize any negative effects on business operations. These events often indicate a deeper underlying problem. For instance, when a server goes down and affects the availability of an application, it would be categorized as an incident.
Additionally, incident and accident are two terms used interchangeably, yet they have distinct definitions in the realm of incident management.
Problem management is the systematic process of identifying and managing the incident causes to prevent such recurrences in the future. These underlying causes are termed 'problems'. Additionally, problem management not only prevents future incidents but also minimizes the impact of incidents that can't be prevented.
In simple terms, if Incident Management is about putting out fires, Problem Management is about understanding what’s causing the fires and how to prevent them in the future.
ITIL, or Information Technology Infrastructure Library, is a set of detailed practices for ITSM that focuses on aligning IT services with the needs of the business. According to ITIL, an incident is a single unplanned event that has caused a service disruption, while a problem is the underlying cause or potential cause of future incidents:
While they're distinct, problem and incident management are also tightly linked. One can't effectively exist without the other. The ultimate goal of both practices is to make sure that the IT service is quality and consistently delivered to the end user.
So, we can sum up that the incident represents the symptoms of the ailment, while the problem represents the ailment itself.
Following the DevOps framework, the lines between problem management and incident management are even more blurred. According to DevOps and its integrated approach, the development team is also responsible for the maintenance. This holistic view ensures the team is not only invested in addressing issues but also in understanding and rectifying underlying (or root) causes.
Change Management is another critical aspect of any mature ITSM approach, that serves as a meta process to your problem and incident management. It ensures that standard procedures are used for efficient and prompt handling of all changes to control IT infrastructure, minimizing the number and impact of any related incidents upon service.
When incidents and problems are identified, Change Management plays a crucial role in ensuring that the solutions and improvements are implemented in a controlled manner, designed to minimize disruptions to IT systems so as to avoid creating future problems. No one wants a fix to one current problem that causes two more down the road.
While there are many different challenges that organizations face when incidents occur, StatusCast has identified the three core problems that cause massive financial loss and operational inefficiency when it comes to incident management. Firstly, insufficient communication during incidents can lead to frustration, confusion, and a breakdown in trust between stakeholders. Without timely and transparent updates, employees and customers are left in the dark, impacting productivity and customer satisfaction. Secondly, A lack of real-time visibility into the status of corporate assets hampers efficient decision-making and prolongs downtime, causing financial losses and dissatisfaction. And lastly, manual tasks, such as assigning tickets and tracking progress, burden employees and hinder critical incident resolution. This results in decreased productivity and prolongs the duration of incidents. StatusCast has developed an approach to managing incidents that addresses these challenges:
Our approach provides organizations with a comprehensive understanding of their IT ecosystem, including the hierarchical relationships and dependencies between various systems and assets. By mapping out this information, teams can prioritize incidents based on their impact and value, allowing them to quickly identify and address high-priority issues. This approach ensures that downtime is minimized, MTTR is reduced and business continuity is maintained. We provide reporting tools and capabilities to help organizations gain visibility into their assets, enabling them to make data-driven decisions during incidents.
StatusCast prioritizes communication, keeping employees and customers informed during incidents, as it is an essential piece of any incident approach that seeks to minimize productivity losses and protect the customer experience. Our incident management solution is built around status pages and proactive, customizable notifications that enable organizations to communicate effectively about critical components and services that are vital to their customers. By providing timely and accurate updates to stakeholders, organizations can manage expectations, build trust, and maintain strong relationships with their employees and customers.
Automation plays a vital role in streamlining the incident management process and ensuring efficient and prompt handling of incidents. StatusCast’s codeless integrations, among other automation capabilities, eliminate repetitive manual processes, such as ticket assignment, incident escalation and root cause analysis (RCA). Leveraging our extensive automation, organizations can quickly identify and resolve incidents, reducing the time it takes to restore disrupted services. Automation not only saves time and money but also improves customer satisfaction by providing quick and accurate information to customers. It also benefits internal support teams by freeing them up from unnecessary support inquiries, allowing them to focus on resolving critical incidents.
When it comes to detecting sudden or ongoing issues and incidents and handling them according to problem management ITIL standards, it's important to know that acting on time prevents or reduces future risks.
Tackling these core problems works to streamline the incident management processes, boost employee productivity, and enable prompt incident resolution. StatusCast’s Incident Management software is laser focused on solving these challenges, in order to empower organizations to maintain seamless operations and mitigate the costs of downtime.
In today's business environment, the continuity of IT systems is crucial to the success of an organization. Unforeseen disasters, such as infrastructure failures or cyber attacks, can severely impact the productivity of your organization. To mitigate these risks, IT departments must develop and implement robust disaster recovery (DR) plans. But, how can you ensure that these plans work effectively in times of crisis? Implementing a regimen of disaster recovery testing ensures that these plans work effectively in a time of crisis.
Disaster recovery testing is essential to verify the reliability and effectiveness of your DR plan. This comprehensive guide will cover the importance of DR testing, various types of tests, and best practices for conducting effective disaster recovery tests.
The primary objective of DR testing is to identify any potential weaknesses or flaws in your disaster recovery test plan, which can then be addressed before an actual disaster strikes. This process minimizes downtime and ensures business continuity. Regular DR exercises also help maintain and update the DR plan, keeping it in sync with the changing IT landscape.
Good reasons to perform yearly disaster recovery testing include:
Understanding the various causes of IT disasters is crucial to developing effective disaster recovery testing scenarios. Here are some common causes of IT disasters and real-world examples of their impact on organizations.
Infrastructure failures: Power outages, cooling system malfunctions, and other infrastructure failures can lead to IT disasters. A notable example is the May 2017 data center power outage that affected British Airways. This incident stranded around 75,000 passengers and disrupted global travel during a busy holiday weekend. You can learn more about this event in this CNBC article.
Cyber attacks: Cyber attacks, such as ransomware and DDoS attacks, can cripple an organization's IT infrastructure and result in data breaches or loss of service. The WannaCry ransomware attack in May 2017 is an example of a massive cyber attack that affected more than 200,000 computers across 150 countries, causing significant disruption to businesses and public services. Read more about the WannaCry attack here.
Hardware failures: Hardware failures, including server crashes and storage corruption, can lead to data loss and prolonged downtime. In 2016, Delta Air Lines experienced a hardware failure that led to a global computer outage, resulting in the cancellation of more than 2,000 flights and an estimated $150 million loss. CNN provides further details on the incident in this article.
Human errors: Accidental data deletion, misconfigurations, and other human errors can cause IT disasters. In 2017, Amazon Web Services (AWS) suffered a significant outage affecting numerous websites and services due to a human error during a debugging operation. The incident highlights the importance of implementing safeguards and training to prevent human errors from causing IT disasters. Learn more about the AWS outage here.
Incorporating a variety of realistic disaster scenarios into your disaster recovery test plan ensures that all aspects of the plan are thoroughly evaluated and helps you better prepare for potential IT disasters.
There are several types of disaster recovery testing, each with its unique benefits and challenges:
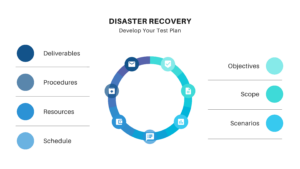
To conduct effective DR exercises, you need a well-structured disaster recovery test plan. This plan should include:
There are several best practices that you should follow to maximize the effectiveness of your DR tests. Testing your disaster recovery plan regularly ensures that it remains effective and up-to-date. Thoroughly document each test, including the objectives, procedures, results, and any issues encountered. Review the disaster recovery test report with key stakeholders to identify areas for improvement. Incorporate any lessons learned from the DR tests into your disaster recovery plan, and ensure it is updated regularly to reflect changes in your organization's IT environment. Train and educate staff to ensure that all team members involved in the DR process are well-trained and familiar with the plan. Leverage automation tools to streamline the testing process and eliminate manual, time-consuming tasks. Verify the integrity of your backups as part of the DR testing process to ensure that you can successfully restore data during a disaster. Establish key performance indicators (KPIs), such as Mean Time to Recovery (MTTR), to measure the effectiveness of your DR plan. Continuously monitor and optimize these KPIs to improve your recovery capabilities.
Root Cause Analysis (RCA) is a critical aspect of disaster recovery testing. RCA involves identifying the underlying factors that led to an IT disaster, which helps organizations learn from past mistakes and prevent future incidents. Incorporating RCA reporting into your DR testing process allows your team to gain valuable insights into potential weaknesses in your systems and processes. By addressing these weaknesses, you can further enhance the resilience and reliability of your disaster recovery plan.
A well-crafted incident response playbook complements your DR testing efforts. The playbook outlines the steps to be taken in response to various incidents, including disasters that require activation of your DR plan. Integrating DR testing with your incident response playbook ensures that your organization is fully prepared to manage any crisis. To learn more about developing an incident response playbook, read our blog post: https://statuscast.com/incident-response-playbook/
Disaster recovery testing is an essential component of a robust IT strategy, ensuring that your organization can quickly recover from unforeseen disasters. By conducting regular tests, you can identify potential weaknesses in your DR plan, maintain compliance with industry regulations, and ensure the continuity of your business operations. Follow the best practices outlined in this guide and leverage powerful tools like StatusCast’s incident response automation to optimize your disaster recovery. Thoroughly test your systems ability to respond to incidents in order to safeguard your organization's future.
When handling and managing IT incidents, it's not just about putting out fires but also digging deeper to prevent those fires from happening again. So, it's time to learn how to perform a safe root cause analysis and analyze the incident retrospectives in order to stop them on time.
Let's get to know the RCA (Root Cause Analysis) better and see how this systematic process helps with uncovering the hidden culprits behind the IT issues.
RCA or Root Cause Analysis is a systematic process designed to uncover the fundamental, underlying issues that lead to IT incidents. These 'root causes' are often masked by surface-level symptoms, making them challenging to identify without a systematic approach. The IT Root Cause Analysis drills past the initial problems to discover deeper, hidden issues and manage the incidents successfully.
Are you finding your team overwhelmed by the same issues despite the repeated attempts to implement workarounds? Does the team waste valuable time on recurring meetings to discuss the same problem over and over again? If the answer to these questions is 'yes,' then probably you're spending more time and effort than you need to. Or, to put it simply, Root Cause Analysis is about making your team work smarter, not harder.
Agile methodologies are centered around the idea of continuous improvement. If your team is conducting regular retrospectives on issues and creating action items that lead to improvement, that's fantastic. But if you're sitting in meeting after meeting, week after week, thinking, "we're still battling the same problem we've been dealing with forever," you may be treating symptoms rather than addressing the real issues. This common pitfall can result in wasted time, energy, and money. By facilitating the identification of real causes, RCA paves the way for solving problems permanently, instead of repeatedly running into the same roadblocks.
Root cause analysis is indispensable in effective incident management by ensuring the resilience of technology-dependent services and operations. What if a critical business application went down unexpectedly because of a failure from a cloud provider your service relies on? Instead of merely reacting to the incident by switching to a backup service or hastily patching the problem, an RCA allows your team to delve into the specifics of the incident and identify the fundamental issues that led to the failure.
Upon investigation, you might find out what the root cause is. It can be a poorly configured system in the cloud service or maybe a capacity issue, where the service could not scale effectively to handle a sudden surge in user requests. And if everything you do is putting out the fire and switching to a backup without a proper root cause analysis retrospective, you risk having the same incident over and over again - with even higher costs to resolve it.
Conducting a systemic root cause analysis also improves the culture of continuous improvement. Each incident becomes an opportunity to learn and improve, creating a proactive stance toward incident management. Over time, this learning and adaptation can lead to more robust systems, improved response times, and, ultimately, better service to customers.
Root Cause Analysis is not a quick-fix solution but a comprehensive process. By running a Root Cause Analysis, you're breaking down a large issue into smaller, more manageable causes. You're digging into each layer of the problem, making it more approachable and easier to tackle. No more getting stuck in a loop of unproductive thoughts or spinning your wheels over things that are out of your control.
Completing a RCA while also running a root cause analysis process mapping ensures your team focuses on the aspects they can change, transforming the frustration into a sense of accomplishment.
To streamline the RCA process, various methods and tools are available, from the Fishbone Diagram and the Five Whys to advanced analytics. RCA analytics leverage machine learning and data to identify patterns and trends, helping teams understand the problem at hand and devise more effective solutions. Various root cause analysis techniques are employed, ranging from cause-effect diagrams to process mapping and Fault Tree Analysis. The choice of technique depends on the nature of the problem and the available data, but each plays an essential role in revealing the root causes of incidents.
Root Cause Analysis, as a methodology, has been articulated and applied in different ways. One useful framework for RCA is the “Fishbone Diagram”, which aids in brainstorming potential causes of a problem and categorizing these causes effectively. The problem, illustrated at the fish's head, has potential causes linked along the smaller 'bones.'
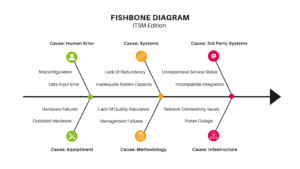
In a Fishbone Diagram, major categories of causes are agreed upon and listed as branches from the main arrow. Each cause is then branched from the appropriate category on the diagram. "Why does this happen?" is asked for each cause, with sub-causes branching off the main ones. This process continues until root causes are identified.
The "Five Whys" is a simple approach to root cause analysis, often used in conjunction with the Fishbone Diagram, that involves asking the question "why?" successively until you reach the underlying cause of a problem. By repeatedly asking "why?" in response to each answer, you can peel back the layers of symptoms which can often obscure the true root cause. This systematic approach ensures that analysis goes beyond surface-level understanding, paving the way for more effective and long-lasting solutions.
Together with the "Five Whys", the Fishbone Diagram keeps teams focused on causes rather than symptoms. This helps teams to see the bigger picture, identify root causes, and devise effective solutions. The Fishbone Diagram is invaluable in its ability to facilitate a deeper understanding of an issue and encourages teams to explore beyond the initial incident report. By using the Fishbone Diagram, teams can identify and address the true issues at hand, preventing similar problems in the future.
SAFe Root Cause Analysis, a key component of the Scaled Agile Framework (SAFe), promotes a systems first approach towards incident retrospectives. By encouraging a collaborative culture, teams learn from past incidents and improve their practices continually. Root cause analysis exercises are a practical and valuable aspect of the scaled agile retrospective, serving as a low-stakes environment for teams to hone their problem-solving skills, prepare for real-world incidents, and build confidence in their abilities.
Root Cause Analysis should be front and center in any comprehensive incident management strategy, and StatusCast has built out automation and advanced functionality around RCAs to do just that. StatusCast provides versatile RCA templates and enables extensive reporting on previous RCAs that isn’t found in any other incident management solutions. The value of early identification of recurring problems cannot be overstated, as it empowers your organization to learn and evolve from previous incidents. StatusCast provides an opportunity to work proactively, assisting your team in eliminating issues that repeatedly affect your business before they cause real harm.
When your users encounter service disruptions, your status page is the first place they look to for answers, and when the issues they face aren’t yet being reported, they are left with no recourse. Our new End-User Incident Reporting, built directly into your status page, makes your users lives easier, and ensures that incidents are reported the moment their impact is felt. This innovative functionality brings the power of two-way communication between your stakeholders and your IT team to your status page. End-User Incident Reporting dramatically improves UX during incidents and reduces incident resolution times.
Click Here to replay our webinar.
As any IT professional knows, detecting and resolving incidents quickly is crucial for maintaining optimal business operations. Often, end-users experience service disruptions before monitoring tools alert IT teams. That's why we've developed end-user incident reporting – a first-of-its-kind feature that turns status pages into a two-way communication hub, empowering users to report issues directly to your IT department.
The true differentiator of our end-user incident reporting lies in its incorporation directly into the status page. As status pages have become the go-to source for checking service status, enabling users to report incidents within the same platform accelerates the reporting process and offers a more user-friendly experience. By eliminating the need for users to search for help desk contacts or a support portal, our new feature makes it easier than ever for stakeholders to report incidents right from your status page.
By bridging the gap between stakeholders and IT teams, End-User Incident Reporting becomes especially useful for large enterprises, managing complex systems and distributed operations across many departments and locations, providing employees with an easy one-step action to report incidents directly to your IT team. This feature turns your incident communication into a two way street, making incidents easier on your users and accelerating your response.
Don't miss this opportunity to learn more about our end-user incident reporting feature and how it can take your status page to the next level.
StatusCast is a leading provider of status page and incident management solutions, dedicated to helping IT professionals communicate efficiently and effectively with their stakeholders during incidents and downtime. With a focus on ensuring that employee and customer productivity stays optimized during outages and maintenance events, StatusCast has become the go-to solution for businesses worldwide seeking to improve their incident management processes. Our platform is built to serve organizations of all sizes, offering tailored solutions that cater to the unique needs of each client.
When services are down, do you really want to be spending valuable time crafting incident messages and status updates? When time is money, your IT team should have one goal in mind: incident resolution. At StatusCast, our mission is to off-load as much excess complexity as possible when incidents strike, to enable your IT department to tackle incidents head on. That’s why we’re excited to announce that we’ve taken StatusCast's IT automation to the next level, with a game-changing feature that will revolutionize the way you manage incidents and keep your stakeholders informed.
Our intent is to help relieve IT teams of the burden of anything that is not directly related to resolving the incident at hand. We don't want you to have to waste time writing incident notifications and managing updates. We envision a growing role for AI in the world of incident management, empowering you to rapidly tackle incidents, without your productivity being crushed by repetitive, ancillary tasks while your service is down.
In today's fast-paced IT environment, the pressure is on for IT professionals to resolve incidents quickly and minimize downtime. However, executing an effective incident communication strategy can often consume valuable time and resources, taking the focus away from the core objective of incident resolution. This is where our AI-powered Smart Incident Messaging comes in, offering a solution that helps IT teams maintain productivity while ensuring clear and consistent communication with stakeholders.
By automating the process of crafting incident notifications, Smart Incident Messaging not only saves time but also minimizes the risk of human error. When you are in the midst of dealing with an incident, it's easy for mistakes to be made in your comms strategy. Our AI assistant mitigates this risk by generating precise and informative messages based on the data provided, ensuring that the right information reaches the right people at the right time.
One of the key benefits of our Smart Incident Messaging is its ability to analyze the tone used in previous incident updates. This ensures that every message it generates maintains a consistent and professional tone, further enhancing the quality of your communication during an incident. This consistency not only improves stakeholder trust but also helps your IT team project a cohesive and well-organized image.
Leveraging our advanced IT automation, StatusCast eliminates repetitive, ancillary tasks that can hinder productivity during downtime. Our AI-powered Smart Incident Messaging empowers IT teams to focus on what truly matters: resolving incidents and restoring normal operations as quickly as possible.
Want to witness the incredible efficiency of our new Smart Incident Messaging for yourself? We hosted a short feature webinar to showcase just how powerful this new capability is. Don't miss this opportunity to get an exclusive first look at how Smart Incident Messaging can transform your incident management process.
With Smart Incident Messaging, you'll be able to streamline your incident management process and keep your stakeholders informed with ease. Join us as we unveil the future of incident management and communication.
StatusCast is a leading provider of status page and incident management solutions, dedicated to helping IT professionals communicate efficiently and effectively with their stakeholders during incidents and downtime. With a focus on ensuring that employee and customer productivity stays optimized during outages and maintenance events, StatusCast has become the go-to solution for businesses worldwide seeking to improve their incident management processes. Our platform is built to serve organizations of all sizes, offering tailored solutions that cater to the unique needs of each client.
In today's digital age, IT departments play a crucial role in maintaining the overall functionality and security of an organization. One essential tool for managing service outages and downtime is the incident response playbook. This comprehensive guide provides IT departments with the necessary processes and strategies to resolve incidents in a timely and efficient manner.
In this blog post, we will explore how to create an effective incident response playbook by incorporating key components such as automated escalation policies, team collaboration, stakeholder communication, and automated runbooks.

An incident response playbook is a roadmap for IT departments to follow when dealing with service outages and downtime. It provides a structured approach to identifying, analyzing, and resolving incidents while minimizing their impact on the organization. A well-designed IR playbook includes a cybersecurity playbook template for various threats and an incident response playbook template to ensure consistency and completeness of the processes.
Learn More About Developing An Effective Incident Response Plan
Book A Demo With Us Today!
Having a proactive escalation policy is essential in the common incident response playbook scenarios. The policy outlines the steps for notifying the responsible individuals within the organization about the incident and consists of:
StatusCast automates the entire execution of the escalation policy, streamlining its incident management process. This ensures the right people are informed and engaged to take action and manage the incident, reducing manual efforts while speeding up the time to incident resolution.
Effective team collaboration is essential during the incident response process. A well-organized IR playbook should emphasize the importance of teamwork and provide guidelines for how IT departments can collaborate effectively.
Key elements of team collaboration include:
Transparent and timely communication with stakeholders is critical during an incident. Typically, IT departments set out to establish their incident communication strategy by doing the following:
StatusCast shortcuts and automates this entire process, offering the most effective form of stakeholder communication through status pages. These provide a centralized platform through which incidents are tracked and communicated autonomously to end users. StatusCast offers three kinds of status pages. Public status pages, which can be utilized to inform customers of downtime, and reduce the overwhelming flood of support requests that your help desk is sure to encounter during service outages. Private status pages, which provide a secure solution for internal incident communication to keep employees informed of their system status. As well as audience-specific pages, which offer more granular views and controls, functioning as custom status pages for each end user. These audience pages ensure that users are provided with only the most relevant information during outages, helping to eliminate alert fatigue and maintain employee productivity.
If you aren't sure about the difference between runbook vs playbook, let's make it clear to you. Runbooks, in general, are an essential component of any incident response playbook. These detailed, step-by-step guides outline the specific actions that IT departments should take to address and resolve incidents.
While incident response runbooks are commonly used among IT departments, StatusCast takes it a step further by automating this component of incident response. With StatusCast, routine and repetitive IT tasks undertaken during an outage are automated, lightening the burden on your IT team as they work toward incident resolution.
StatusCast's automated incident response playbook enhances an organization's efficiency by ensuring a consistent process for resolving incidents. With that, our incident playbook is allowing IT teams to focus on more complex and critical tasks that require their expertise.
To create a truly effective incident response playbook, it's essential to incorporate various scenarios that cater to the different types of threats an organization may face. These scenarios should include cyber security playbook examples and incident response examples, such as dealing with DDoS attacks, malware, data breaches, and more.
Each scenario should be documented with detailed instructions on how to address the specific threat, the roles and responsibilities of team members, and the expected timeline for resolution. Regularly reviewing and updating these scenarios ensures that the playbook remains current and relevant, allowing IT teams to respond effectively to new and emerging threats.
A cybersecurity playbook template is a vital tool for maintaining consistency and completeness across an organization's incident response strategy. By using a standard template, IT departments can ensure that all the necessary components and steps are included in each security playbook, regardless of the specific threat being addressed.
A comprehensive cybersecurity playbook template should include:
Ransomware attacks are becoming increasingly common and can have severe consequences for organizations. A ransomware playbook flowchart is a valuable addition to any incident response playbook, as it provides a visual guide for IT departments on how to address ransomware threats effectively.
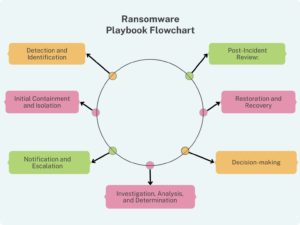
A ransomware playbook flowchart should include the following key steps:
In this blog post, we discussed the importance of creating an effective incident response playbook to guide IT departments in addressing service outages and downtime. Key components of a comprehensive playbook include escalation policies, team collaboration, stakeholder communication, and runbooks. We emphasized the significance of incorporating incident response scenarios, utilizing a cybersecurity playbook template, and implementing a ransomware playbook flowchart to enhance preparedness, maintain consistency, and streamline ransomware incident response. This, in turn, helps minimize the impact of incidents on the organization and ensures the ongoing security and functionality of its digital infrastructure. By incorporating these elements, IT departments can ensure a structured approach to identifying, analyzing, and resolving incidents, minimizing their impact on the organization.
Mean Time To Repair, or MTTR, is a critical metric in IT incident management that measures the average time it takes to fix a system failure. The meaning of MTTR can be understood as the average duration needed for an IT team to recover from an incident. It is a fundamental metric for IT teams to track and analyze their efficiency in resolving incidents. MTTR is also an essential component of the bigger incident management lifecycle for IT departments, which includes identifying, prioritizing, diagnosing, fixing, and documenting incidents. In this blog post, we'll explore what MTTR is, why it's important, how to calculate MTTR, and what teams can do to reduce it.
MTTR, sometimes referred to as mean time to recovery or mean time to recover, is critical because it provides insights into the efficiency and effectiveness of an IT team's response to an incident. By tracking MTTR, IT teams can identify where bottlenecks occur and take corrective measures to improve the incident management process. A high MTTR may indicate failure points in the incident management process, such as delays in communication, inadequate resources, or poor documentation. On the other hand, a low MTTR indicates efficient incident response, which leads to increased system uptime and improved user experience.
Measuring MTTR requires identifying the start and end points of an incident, such as the time an incident was reported and the time the incident was resolved. This metric is typically calculated by dividing the total time taken to resolve an incident by the number of incidents resolved during that period.
As we introduce new terms, we'll now have to explain what MTFB and MTTR mean, while sharing some tips on how to reduce MTTR and improve the overall reporting and resolving the ongoing IT issues.
It's important to note that MTTR is not the same as Mean Time Between Failure (MTBF) or Mean Time To Failure (MTTF), as MTBF and MTTF can be different, depending on the definition of MTBF being used, As we introduce new terms, we'll now have to explain what MTFB and MTTR mean, while sharing some tips on how to reduce MTTR and improve the overall reporting and resolving the ongoing IT issues.
While Mean Time Between Failures (MTBF) is often mentioned alongside MTTR, it is essential to note that this metric has two commonly used definitions. These definitions can lead to different interpretations of system reliability and dependability. We will explore these definitions and discuss the pros and cons of each.

The first definition of MTBF refers to the operational hours between the end of the last incident and the beginning of the next incident. This definition focuses on the actual uptime of a system or component, excluding the time it takes to repair or replace it. This approach offers a more optimistic view of system reliability and may be more suitable for measuring non-critical systems where downtime doesn't significantly impact business operations.
Pros:
Cons:

The second definition of MTBF involves the total time between each failure, from the start of one incident to the start of the next. This approach provides an idea of how frequently incidents occur, including the time it takes to repair or replace a component. This definition is more conservative and can be a better fit for measuring critical systems where downtime has a significant impact on business operations.
Pros:
Cons:
In conclusion, the choice of MTBF definition depends on the context in which it is applied and the specific objectives of the organization. For non-critical systems, using the first definition may be more relevant, while the second definition can be more appropriate for critical systems. Understanding the pros and cons of each definition can help organizations choose the most suitable metric for their needs, ensuring they accurately assess their system reliability and make informed decisions about maintenance, investment, and incident management.
On how to reduce MTTR, IT teams should take some measures, like investing in automation tools to speed up incident resolution. Also, they need to improve communication channels between teams while creating a well-documented incident management process and conduct regular training on the topic. It's also essential to prioritize incidents based on their impact on the business and allocate the necessary resources to resolve them efficiently.
Several solutions are available to help teams reduce MTTR in IT, such as incident management software, monitoring services and automation tooling. Incident management software provides a centralized platform to track and manage incidents, assign tasks, and communicate with teams. Reporting tools help identify incidents before they affect users and reduce the time it takes to diagnose and resolve them. Automation can help speed up incident resolution by automating routine tasks, such as restarting servers or running diagnostic tests.
An internal private status page is also an effective tool that can help reduce MTTR by enabling employees to track the progress of an outage from start to finish. This page can provide real-time updates on the status of an incident, including the steps being taken to resolve it and the estimated time to resolution. This allows employees to stay informed about the incident, reducing the number of support calls and emails received by the IT team. Moreover, employees can get a sense of how long an incident may take to be resolved, which can help them plan their work around the outage. By providing transparency into the incident management process, an internal private status page can help increase employee confidence in the IT team's ability to resolve issues quickly and efficiently, which can ultimately lead to a faster MTTR.
In addition to providing transparency into the incident management process, an internal private status page can also help reduce the noise and distractions that IT teams face when trying to resolve an incident. By proactively communicating updates and progress on the incident through the status page, employees are less likely to contact the IT team with questions or concerns. This helps reduce the volume of support calls and emails, which can often be a significant distraction for IT teams during an incident. By freeing up the IT team's time and resources, they can focus on resolving the incident more efficiently, which can lead to a faster MTTR. An internal private status page not only provides a centralized platform for employees to track the progress of an incident, but it also helps reduce the noise and distractions that IT teams face during an outage, leading to a faster resolution time.
In conclusion, Mean Time To Resolution is a critical metric in IT incident management that measures the average time it takes to fix a system failure or issue. It provides insights into the efficiency and effectiveness of an IT team's response to an incident and is essential for improving incident management processes. To reduce MTTR, IT teams can take several measures, such as investing in automation tools, improving communication channels, and creating a well-documented incident management process. By tracking and reducing MTTR, IT teams can improve system uptime and user experience, which ultimately leads to a more productive and profitable business.
The IT Team for a large organization plays a crucial role in ensuring the smooth operation of the company’s technology infrastructure, hence securing a robust system status management. One important aspect of their job is incident management, which involves identifying, assessing, and resolving issues that arise with the technology systems. IT teams utilize status pages to interface with end-users in order to inform them of system status, downtime and maintenance. Most status pages are public by default, and offer unrestricted access to a company’s service status. Whereas private status pages utilize permissions based access to protect sensitive information, while keeping relevant users optimally informed.
Having private pages is an essential part of an effective incident management process and policy. Here are the top five reasons why:

Lost employee productivity: One of the biggest costs of IT outages is lost employee productivity. A private status page allows the IT team to keep stakeholders informed about the sensitive status of ongoing incidents and the actions being taken to resolve them. This level of transparency helps to minimize confusion and uncertainty in internal communication among employees and partners, which helps to reduce resource and productivity loss.
Transparency: A private status page allows the IT team to keep only the relevant stakeholders informed about the status of ongoing incidents and the actions being taken to resolve them. This level of transparency is important for building trust with stakeholders and maintaining a positive reputation for the IT team.
Communication: A private status is the backbone of internal incident communication that organizations count on when services go down. Configured audience groups and escalation policies cut through the noise and ensure that the right people are optimally informed. This helps to reduce confusion and keep the right people informed.
Accountability: A private status page allows the IT team to document their actions and decisions during an incident. This documentation establishes accountability, identifies areas for improvement, and creates a feedback loop to improve an organization's future incident response.
Reputation management: A private status page allows a private status monitor for the IT team to proactively manage the organization’s reputation during an incident. By keeping stakeholders informed and maintaining transparency throughout the incident, the IT team can minimize any damage to the organization's reputation.
Leveraging a private status page is an essential part of any effective incident management role and process for a large organization’s IT team. It reduces lost employee productivity with transparent communication and protects organizational reputation when infrastructure goes down. This ultimately leads to a more efficient, effective, and reliable incident management process, and ultimately, a more successful organization. See what's possible with a status page from some of our customers.
© Copyright StatusCast 2022 | Terms & Conditions | Privacy Policy