


Incident Management and Problem Management are two concepts that take an integral part of the IT service management, or shortly, ITSM. Even though they seem similar, and many will use the terms incorrectly, they have different purposes.
This blog post will help you understand the differences between Incident Management vs Problem Management. As a result, you will learn how to apply these concepts in your own approach to handle incident management.
Defining the Terminologies
Before we explain the difference between incident and problem management, we must define the terminology to understand each term easily and what it refers to.
Shortly, incident management deals with issues that come up suddenly, while problem management focuses on the root causes behind those incidents.
But let's explain these terms before diving deeper into the topic.
What is Incident Management?
Incident Management is the process of addressing and resolving unplanned events or interruptions affecting the quality of an IT service. The primary goal is to regain normal service operations and minimize any negative effects on business operations. These events often indicate a deeper underlying problem. For instance, when a server goes down and affects the availability of an application, it would be categorized as an incident.
Additionally, incident and accident are two terms used interchangeably, yet they have distinct definitions in the realm of incident management.
What is Problem Management?
Problem management is the systematic process of identifying and managing the incident causes to prevent such recurrences in the future. These underlying causes are termed 'problems'. Additionally, problem management not only prevents future incidents but also minimizes the impact of incidents that can't be prevented.
In simple terms, if Incident Management is about putting out fires, Problem Management is about understanding what’s causing the fires and how to prevent them in the future.
ITIL Distinctions Between the Two
ITIL, or Information Technology Infrastructure Library, is a set of detailed practices for ITSM that focuses on aligning IT services with the needs of the business. According to ITIL, an incident is a single unplanned event that has caused a service disruption, while a problem is the underlying cause or potential cause of future incidents:
- ITIL Incident Management:
In ITIL, Incident Management is primarily concerned with getting the affected services back on track as quickly as possible. It’s a reactive process - it’s about efficiently responding to an incident, ensuring it has as little impact on service quality and customer experience as possible.
- ITIL Problem Management:
ITIL's Problem Management, on the other hand, is more proactive. It’s about identifying and resolving the root cause of incidents. This involves performing an ITIL root cause analysis, identifying patterns and trends, and implementing workarounds and solutions.
Problem Management vs Incident Management: An Interwoven Relationship
While they're distinct, problem and incident management are also tightly linked. One can't effectively exist without the other. The ultimate goal of both practices is to make sure that the IT service is quality and consistently delivered to the end user.
So, we can sum up that the incident represents the symptoms of the ailment, while the problem represents the ailment itself.
DevOps: Bridging Incident and Problem Management
Following the DevOps framework, the lines between problem management and incident management are even more blurred. According to DevOps and its integrated approach, the development team is also responsible for the maintenance. This holistic view ensures the team is not only invested in addressing issues but also in understanding and rectifying underlying (or root) causes.
The Role of Change Management
Change Management is another critical aspect of any mature ITSM approach, that serves as a meta process to your problem and incident management. It ensures that standard procedures are used for efficient and prompt handling of all changes to control IT infrastructure, minimizing the number and impact of any related incidents upon service.
When incidents and problems are identified, Change Management plays a crucial role in ensuring that the solutions and improvements are implemented in a controlled manner, designed to minimize disruptions to IT systems so as to avoid creating future problems. No one wants a fix to one current problem that causes two more down the road.
StatusCast’s Approach to Incident Management
While there are many different challenges that organizations face when incidents occur, StatusCast has identified the three core problems that cause massive financial loss and operational inefficiency when it comes to incident management. Firstly, insufficient communication during incidents can lead to frustration, confusion, and a breakdown in trust between stakeholders. Without timely and transparent updates, employees and customers are left in the dark, impacting productivity and customer satisfaction. Secondly, A lack of real-time visibility into the status of corporate assets hampers efficient decision-making and prolongs downtime, causing financial losses and dissatisfaction. And lastly, manual tasks, such as assigning tickets and tracking progress, burden employees and hinder critical incident resolution. This results in decreased productivity and prolongs the duration of incidents. StatusCast has developed an approach to managing incidents that addresses these challenges:
The Asset First Approach
Our approach provides organizations with a comprehensive understanding of their IT ecosystem, including the hierarchical relationships and dependencies between various systems and assets. By mapping out this information, teams can prioritize incidents based on their impact and value, allowing them to quickly identify and address high-priority issues. This approach ensures that downtime is minimized, MTTR is reduced and business continuity is maintained. We provide reporting tools and capabilities to help organizations gain visibility into their assets, enabling them to make data-driven decisions during incidents.
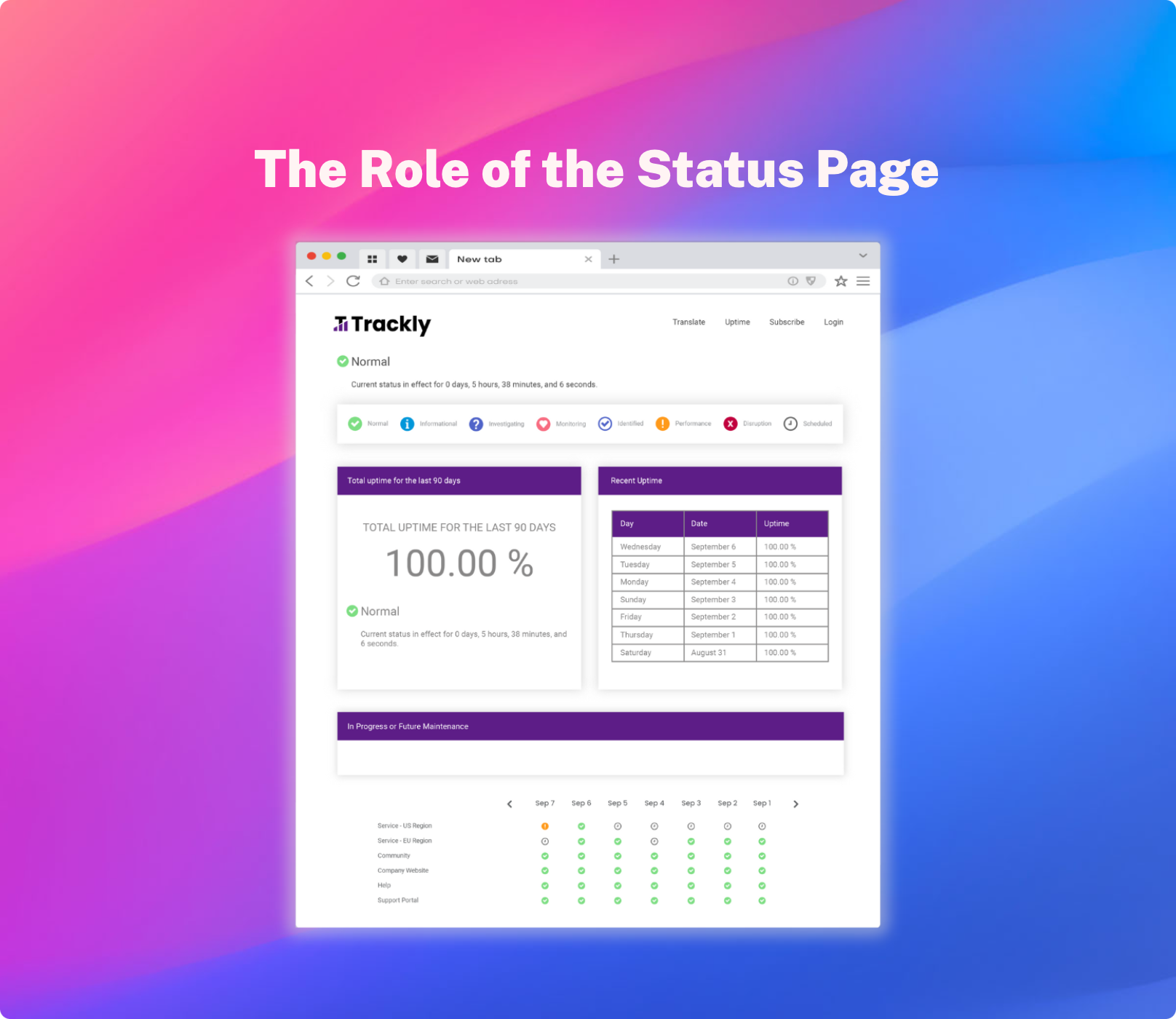
Stakeholder Communication
StatusCast prioritizes communication, keeping employees and customers informed during incidents, as it is an essential piece of any incident approach that seeks to minimize productivity losses and protect the customer experience. Our incident management solution is built around status pages and proactive, customizable notifications that enable organizations to communicate effectively about critical components and services that are vital to their customers. By providing timely and accurate updates to stakeholders, organizations can manage expectations, build trust, and maintain strong relationships with their employees and customers.
Automation
Automation plays a vital role in streamlining the incident management process and ensuring efficient and prompt handling of incidents. StatusCast’s codeless integrations, among other automation capabilities, eliminate repetitive manual processes, such as ticket assignment, incident escalation and root cause analysis (RCA). Leveraging our extensive automation, organizations can quickly identify and resolve incidents, reducing the time it takes to restore disrupted services. Automation not only saves time and money but also improves customer satisfaction by providing quick and accurate information to customers. It also benefits internal support teams by freeing them up from unnecessary support inquiries, allowing them to focus on resolving critical incidents.
Our Thoughts on Incident vs Problem Management
When it comes to detecting sudden or ongoing issues and incidents and handling them according to problem management ITIL standards, it's important to know that acting on time prevents or reduces future risks.
Tackling these core problems works to streamline the incident management processes, boost employee productivity, and enable prompt incident resolution. StatusCast’s Incident Management software is laser focused on solving these challenges, in order to empower organizations to maintain seamless operations and mitigate the costs of downtime.