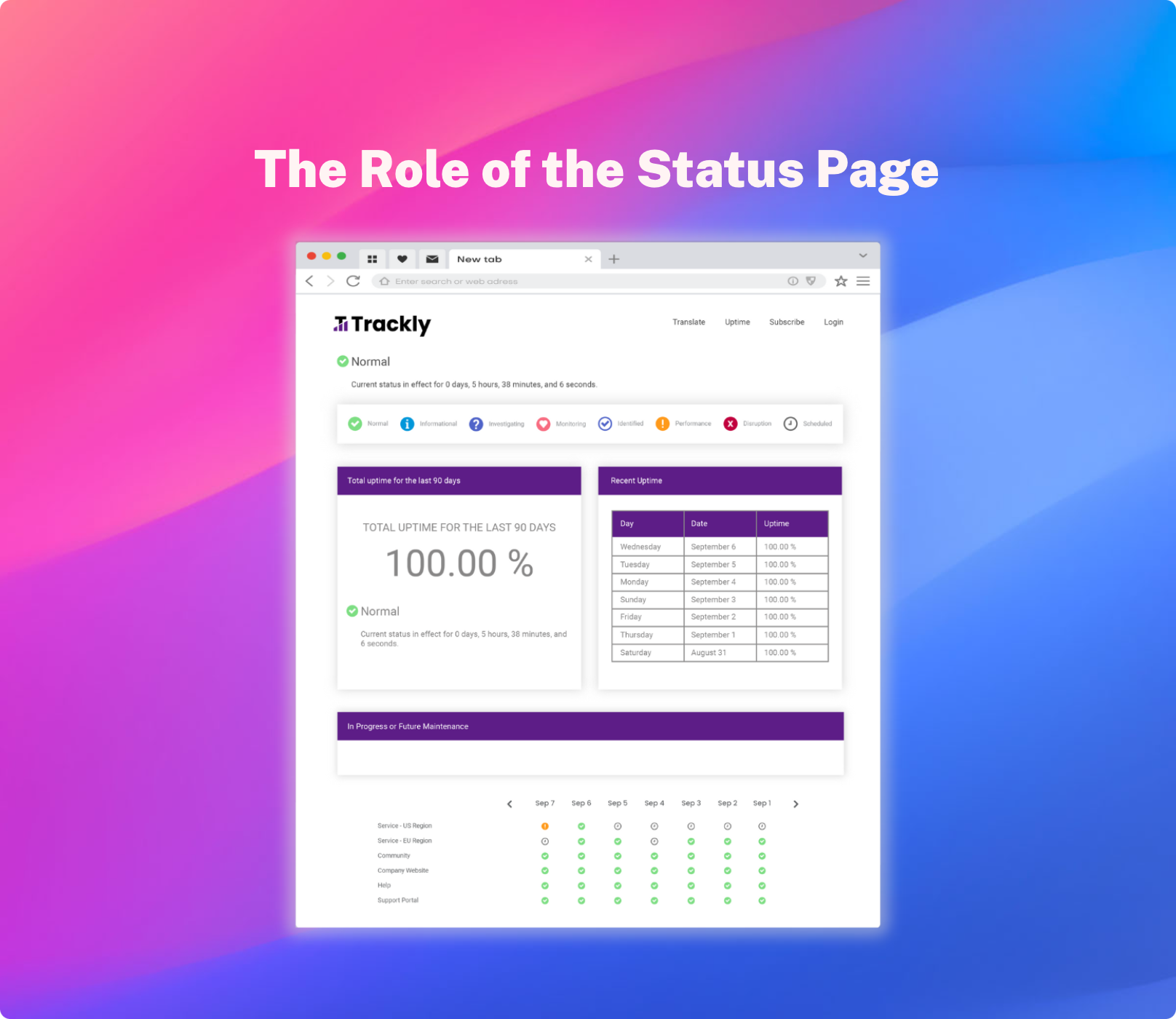
At any moment, a small failure at any point in your complex web of IT systems can trigger an outage. As such, proactively establishing a method of clear and timely end user communication is the crux of effective incident response. For large organizations, these moments of downtime not only carry a massive opportunity cost, but also test the resilience of their operations. This is the point at which a status page can decide the outcome of an incident; is the incident a blip on the radar, or does it cascade into business failures that disrupt your entire organization and leave a lasting stain on your brand image in the mind of your customers. While your IT team relies on an incident management system internally to work toward resolving incidents, the status page acts as the front-end of your incident response, the external interface between IT and end users, keeping them informed of disruptions before they encounter them.
Employees stand at the frontline, directly impacted by IT incidents that can disrupt their daily operations and workflows. Simultaneously, the impact on employees can represent the greatest cost of outages in the form of lost productivity. The status page serves as a crucial bridge between IT and other employees, connecting them with real-time updates and guidance amidst the tumult of chaos. When employees are kept in the loop during downtime, the path forward is illuminated and they are empowered to adapt workarounds and implement contingency plans. This helps to safeguard productivity and keep critical business operations that your employees tend to humming along. In essence, the status page ensures that your workforce remains informed, engaged, and equipped to navigate through disruptions without succumbing to the disruption of downtime.
For SaaS customers, the impact of IT incidents can disrupt critical processes and delay projects, which degrades customer experience and leads to churn. When services that customers rely on face disruptions, they can turn to the status page which offers real-time updates on ongoing issues, archives historical data on past incidents for context, and proactively notifies users about scheduled maintenance. This status page acts as a single-source-of-truth, which is an invaluable resource for SaaS providers to offer their customers, as their experience hinges on a complex web of interwoven services. By having access to detailed, real-time information, customers can quickly understand the nature and extent of any outage or degradation. This enables them to make informed decisions, perhaps activating alternative plans or adjusting timelines to mitigate the impact on their own clients and stakeholders. The status page helps to set clear expectations with updates and visibility into critical systems, which mitigates customer frustration during outages.
Tasked with the monumental responsibility of navigating incident resolution, the status page significantly lightens the burden on IT by automating the outreach to stakeholders. Status page automation not only streamlines communication, freeing IT professionals to concentrate on solutions, but also aggregates crucial data from APM and Observability tools. By funneling this diverse information into a single, centralized platform, the status page minimizes the complexity of incident management. It emerges as a single pane of glass that IT can view incidents through, enabling them to efficiently pinpoint issues, strategize resolution, and ultimately, enhance the organization's capacity to withstand and recover from downtime.

A cornerstone of any effective status page is its ability to proactively notify stakeholders of incidents, updates, and resolutions. This ensures that information is pushed to end-users without requiring them to seek it out, thereby enhancing the effectiveness of such communications in producing efficiency savings and mitigating disruptions in normal operations for end users.
A status page integrates third-party status information offering a comprehensive view of the IT ecosystem, highlighting dependencies and potential points of failure. This integration is crucial for maintaining a seamless picture of critical services and makes life easier on users who no longer have to independently check the status of multiple different third party services.
For internal stakeholders, a private status page provides a secure, permissions-based platform for communication. This ensures that sensitive information is shared with discretion, fostering an environment of trust and accountability within the organization.
Above all, a status page serves as a single-source-of-truth for end-users facing service disruptions. It offers a comprehensive view of all critical systems, components, and third-party services, displaying real-time data on their status. This clarity is invaluable, as is the consolidation of this information in one location, guiding stakeholders through the incident with maximum visibility.
A status page is a cornerstone of effective incident management. It facilitates a proactive approach to incident communication, enabling organizations to inform stakeholders about the status of services they rely on. The status page automates various aspects of this process, from the distribution of notifications to the integration of monitoring tools that identify incidents in the first place. This automation significantly reduces the burden on IT in the moment that they are under the most pressure, freeing them up to focus solely on resolving outages.
Moreover, a private status page is instrumental in internal incident communication, ensuring that the right people are optimally informed. It establishes accountability, identifies areas for improvement, and creates a feedback loop to enhance an organization's future incident response capabilities.
The incident resilience of an organization is measured not just by its ability to reduce the total amount of downtime they experience, but by its ability to reduce the magnitude of the impact of downtime when it does occur. The status page emerges as a critical tool in this endeavor, mitigating the effects of outages that degrade end user productivity and customer experience. By providing a real-time interface between IT departments and various stakeholders from employees to customers, it ensures that all stakeholders remain informed, engaged, and empowered to navigate the challenges of IT disruptions.
With the growing complexity of IT systems, managing alerts and notifications without succumbing to the crippling effects of alert fatigue has never been more challenging. Alert Fatigue occurs when the volume of notifications makes it impossible to discern signal from noise, desensitizing the recipient to warnings, some of which end up representing critical issues.
Alert fatigue manifests when the following conditions are met:
→ There exists a high volume of alerts
→ Most of these alerts are of little significance
This not only hampers productivity, but also elevates the risk of overlooking critical alerts that get buried in the noise. The root causes of Alert Fatigue include:
Monitoring Entropy: Dependence on a large set of scattered monitoring tools, all of which IT must tend to, which leads to inefficiency and by default excessive notifications, not all of which are actionable or relevant.
Poor Alert Configuration: Inadequately configured alert thresholds lead to a flood of unnecessary warnings.
Lack of Prioritization: Treating all alerts with equal importance, making it difficult to identify and respond to the most critical issues promptly.
The consequences of Alert Fatigue extend beyond mere inconvenience, potentially leading to:
Delayed Response Times: Critical alerts may be lost in the noise, delaying response to incidents that could affect business operations.
Increased Risk of Burnout: Constantly managing a barrage of alerts can lead to IT professional burnout, reducing productivity and job satisfaction.
Eroded Trust in Monitoring Systems: Over time, IT teams might begin to ignore alerts, assuming them to be false alarms, which could undermine the effectiveness of monitoring systems.
One of the most effective strategies to mitigate Alert Fatigue involves automating the integrations of APM and Observability tools. The relentless stream of alerts from these systems can quickly overwhelm IT personnel, making it challenging to distinguish between routine notifications and signals of genuine issues. By implementing automation, organizations can pre-configure rulesets that automatically evaluate and process alerts based on defined criteria. This ensures that only the alerts surpassing a specific threshold of importance or urgency are brought to the attention of IT staff. StatusCast Beacons enable codeless integrations with monitoring tools, filtering monitoring data and creating a single pane of glass for IT to view all their monitoring.
Adopting an asset-first approach prioritizes alerts based on the criticality of the affected assets, ensuring that IT resources are allocated efficiently towards maintaining essential services. This methodology involves a shift in perspective, from reacting to individual incidents to maintaining the overall health and functionality of key components within the IT infrastructure. By focusing on the assets most critical to business operations, a triage effect is created that automatically prioritizes certain alerts and filters out others. To further refine incident notifications, escalation policies become straightforward when certain teams or individuals are made responsible for certain assets, reducing the need for everyone to receive a specific alert. This strategic focus on assets not only streamlines incident notifications, but also aids in resource optimization, ensuring that the most vital elements of the IT ecosystem receive immediate attention. Check out our New Approach to Incident Management for a more holistic view of the asset-first approach.
The implementation of personalized notifications for end users represents a paradigm shift in how information about IT incidents is communicated. By leveraging audience groups and component subscriptions, organizations can ensure that end users only receive notifications regarding services or components they rely on. This targeted communication strategy significantly reduces alert fatigue among end users, as they are not bombarded with updates about every incident, when most incidents do not impact them directly. When end users get alerts, they can be sure that it is because they are directly affected by an incident. Personalized notifications enhance the user experience by providing relevant, timely information, enabling users to make informed decisions about their work in the context of ongoing IT issues.
In conclusion, while alert fatigue presents a formidable challenge in the realm of IT systems and incident response, it is not insurmountable. By understanding its causes and implementing strategic solutions, organizations can mitigate its impact. Automating APM & Observability integrations, taking an asset-first approach, and leveraging personalized notifications for end users are pivotal steps towards navigating the challenge of alert fatigue. With these measures, IT teams can ensure that they remain responsive to critical alerts, safeguarding the integrity of their IT ecosystems and supporting the seamless operation of their organizations.
In the realm of IT, disruptions and outages are not just inconveniences—they are critical events that can undermine the operations of businesses, impacting services, and user experiences. The landscape of IT incidents is vast, encompassing everything from minor glitches to significant outages that can halt operations and cascade into major business failures. Recognizing that there are various potential culprits for these disruptions, this blog will delve into the myriad causes of IT incidents.
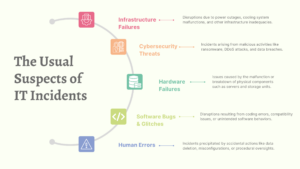
1. Infrastructure Failures:
Infrastructure failures stand as a primary catalyst for IT incidents, encompassing a wide spectrum from power outages to cooling system breakdowns. The backbone of IT operations, physical infrastructure, is susceptible to various unforeseen failures that can precipitate significant downtime. These failures often result from a complex interplay of outdated equipment, maintenance oversights, or environmental factors. The fallout can be dramatic, disrupting essential services and leading to operational paralysis. Recognizing the vulnerabilities inherent in the infrastructure your organization relies upon is pivotal in crafting proactive strategies to mitigate the severity and duration of such disruptions.
2. Cybersecurity Threats:
The digital domain is perpetually under siege from a range of cybersecurity threats, forcing organizations to constantly battle to protect their data and systems from malicious attacks. Cyber threats encompass a broad range of malicious activities, including ransomware, phishing, DDoS attacks, and more. These attacks exploit vulnerabilities within the system, seeking to compromise, steal, or ransom sensitive information. The impact of such threats extends beyond immediate data loss or service disruption; their impact on daily operations and service integrity can erode stakeholder trust and incur substantial financial and reputational damage.
3. Hardware Failures:
Hardware failures represent a tangible risk to IT services, where the malfunction of physical components like servers, storage units, or networking hardware can lead to substantial data loss and service interruptions. Unlike software issues that might be patched remotely, hardware failures often require physical interventions, making the recovery process more prolonged and complex. These failures might stem from natural wear and tear, manufacturing defects, or inadequate environmental controls.
4. Software Bugs and Glitches:
Software bugs and glitches represent a pervasive challenge in the IT landscape, where even minor programming errors can lead to catastrophic service disruptions to end user applications. These anomalies within software applications or operating systems can trigger a cascade of problems, ranging from minor user interface issues to critical security vulnerabilities or complete system crashes. The origins of these bugs are diverse, stemming from complex codebases, compatibility issues across different environments, or unintended interactions between various software components. Given the intricacy of modern software and the rapid pace of development, identifying and rectifying these bugs requires diligent testing, continuous monitoring, and timely updates.
5. Human Errors:
Human errors are an often-underestimated source of IT incidents, encompassing a range of mistakes from accidental data deletion to configuration errors. The complexity of IT systems, combined with the possibility of oversight or misunderstanding, can lead to significant unintended consequences. These errors highlight the importance of addressing the human element in IT operations, which involves fostering a culture of vigilance and continuous learning, aiming to minimize the risk of errors that could lead to widespread disruptions.
StatusCast redefines IT incident communication through its centralized status page, offering an integral platform for real-time updates on the status of critical components and services. By acting as a single-source-of-truth, it becomes an indispensable resource for employees or customers experiencing IT disruptions, ensuring they have immediate access to accurate and current information. This transparency is key to reducing frustration and building trust during downtime, as stakeholders are consistently informed about the state of IT services. Effective incident communication also helps to minimize lost employee productivity during outages; by keeping stakeholders informed, organizations empower their teams to activate contingency plans swiftly, maintaining business operations with minimal disruption. This strategic approach to communication not only enhances operational resilience but also reinforces stakeholder confidence in the organization's ability to manage IT incidents.
The platform's capability to dispatch preemptive notifications about planned maintenance ensures users are well-prepared for potential disruptions. StatusCast also enables various strategies for highly personalized notifications, from component subscriptions to audience groups and custom status page views; which all make it possible for those affected by IT disruptions to be notified and kept in the loop before they encounter an outage themselves, preventing uncertainty and frustration among stakeholders.
StatusCast offers out-of-the-box integrations with various APM and Observability platforms. It acts as a sophisticated conduit, funneling essential data from a variety of sources into a single pane of glass, drastically mitigating technical debt and complexity in the incident management process. This enables IT teams to effectively filter, prioritize, and respond to alerts without juggling multiple systems or succumbing to alert fatigue; by ensuring comprehensive visibility and seamless coordination across teams and tools, StatusCast minimizes IT downtime and bolsters operational resilience.
StatusCast has built out automation and advanced functionality around Root Cause Analysis (RCA), enabling businesses to not just react to IT incidents, but to proactively prevent their recurrence. Recognizing the exhaustive cycle of addressing repetitive issues, StatusCast’s RCA functionality is designed to empower organizations to work smarter, not harder. It provides versatile RCA templates and unparalleled incident reporting capabilities, making it a unique offering in the incident management space. This focus on post incident analysis allows teams to identify and dissect the underlying causes of incidents—be it infrastructure misconfigurations, scalability issues, or external dependencies—thereby transforming temporary workarounds into long-term solutions. With StatusCast, organizations gain the ability to anticipate potential problems through early identification of recurring patterns, facilitating a shift from reactive measures to a proactive stance.
In navigating the complex landscape of IT incidents, understanding potential causes and implementing a proactive incident management strategy are paramount. StatusCast's new approach to incident management, and it's battled tested ITSM products, provides an unparalleled incident response stack that can help businesses mitigate the significant costs of IT outages. As organizations continue to adapt to the challenges of IT incidents, IT departments that embrace solutions like StatusCast will be ahead of the game in building a more resilient and robust IT infrastructure, safeguarding critical business operations and maintaining the trust of their stakeholders when systems go down.
In our interconnected world of technology, where we work tirelessly even on this Valentine’s Day, the reliance of our businesses on digital platforms and services has never been greater. Amidst this, the efficiency and efficacy of large organizations depend on openness and transparency from their IT systems and the professionals managing them. One of the unsung heroes in this realm is the often-overlooked status page. This blog aims to explore the significance of status pages and why giving them a little extra love can make a substantial difference in our digital experiences.
Behind every app, website, or online service lies a complex network of servers, databases, and infrastructure working tirelessly to deliver seamless experiences to users. However, these systems are not infallible, and issues can arise. The status page serves as the window into this otherwise invisible world, providing users with a single pane of glass to keep their finger on the pulse of all the systems they depend on when things go down. Keeping our stakeholders updated on the health and performance of critical systems, as well as real-time updates of underlying IT issues.
In the digital age, we all are in need of love and instant gratification. When an application encounters difficulties, users want to be informed promptly. A well-maintained status page acts as a communication hub, delivering real-time updates about scheduled maintenance, ongoing incidents and their resolution. This transparency not only keeps users informed but also fosters trust by demonstrating a commitment to open communication.
Get a glimpse of what your status page might look like
Check out our favorite Status Page Examples!
Love is often about understanding and managing expectations. Status pages do just that in the IT realm. By providing users with information about potential disruptions or maintenance schedules, these pages help manage expectations and prevent frustration. Users are more forgiving when they are aware of ongoing issues and understand that steps are being taken to resolve them.
A status page empowers users by putting information at their fingertips. Instead of relying on social media or customer support channels for updates, users can independently check the status page, or subscribe to specific components and services that matter to them for notifications, to get the most accurate and up-to-date information. This autonomy enhances the overall user experience, giving users recourse when they encounter disruptions, allowing individuals to make informed decisions based on the current status of a service.
In any relationship, trust is paramount. The same holds true for the relationship between users and digital services. Regular updates on a status page demonstrate a commitment to transparency, showing users that their experiences and concerns are taken seriously. This transparency, in turn, builds trust and loyalty, essential elements in sustaining any successful digital service.
As we celebrate the spirit of connection this Valentine's Day, let's extend our gratitude towards the often-unseen hero of our digital workspaces—the status page. This beacon of transparency and trust mirror the dedication and love IT professionals invest in ensuring our digital world keeps humming along. By leveraging the status page, we can foster a more informed and resilient digital landscape for our customers. In recognizing the vital role of status pages, we celebrate the essence of professional care and connection that keeps our digital lives harmoniously intertwined. So, the next time your users encounter an IT outage, remember a status page can be their lifeline, and your opportunity to show them love when they need it most.
Downtime is an inevitable reality in the fast-paced world of Information Technology. When systems go offline, the pressure mounts, and colleagues begin to bombard IT professionals with the dreaded question: "Are you down?" The good news is that there's a way to transform this frustrating situation into an opportunity to shine.
By implementing a Private Status Page from StatusCast, you can not only proactively communicate issues to affected employees, but also position yourself as the office hero. In this blog, we'll explore the challenges of IT downtime and how a status page can be your secret weapon.
IT downtime is like the ghost that haunts every tech professional's nightmares. Whether it's a server crash, a software glitch, or a network failure, downtime disrupts business operations and can lead to significant financial losses. However, the real challenge often lies in managing the flood of inquiries from colleagues, all asking the same question: "Are you down?"
Picture this: Your team is working tirelessly to resolve an unexpected IT issue. As you're knee-deep in troubleshooting, your inbox starts filling up with messages from various departments, all seeking reassurance or updates. The constant interruptions hinder your ability to focus on resolving the problem promptly.
StatusCast, a leading status page provider, offers a simple yet powerful way to transform your approach to managing downtime. By creating a dedicated status page, you can provide real-time updates on the status of internal systems and components , third party services, and resolutions. This proactive communication not only keeps your colleagues informed but also reduces the influx of repetitive questions.
Leverage a status page to communicate incidents before employees experience the frustration of encountering an unexpected issue, leading to a flood of questions in your inbox. A status page keeps everyone in the loop, reducing anxiety and frustration across the organization.
A status page provides transparency within your organization, updating those affected by ongoing issues via personalized notifications and acting as a single-source-of-truth that all employees can count on when their normal activities are derailed. Being open during incidents builds trust among your colleagues and showcases your commitment to resolving problems efficiently.
IT professionals report that they lose roughly 12 minutes after an incident crafting notifications, a time that can be multiplied many times over as follow-on updates have to be created and support requests answered. StatusCast enables pre-made content templates for incident notifications, and automatically distributes them to specific subscribers or audiences - fully automating a time sensitive task in order to keep IT free to focus on resolving the incident.
Many IT departments at large enterprises have to manage a complex web of critical services, and many in-house or cheap ITSM tools are halfway solutions that end up incurring a lot of technical debt. StatusCast integrates with various APM & Observability tools out of the box, reducing complexity for IT personnel by providing a single pane of glass for all monitoring.
Tailor your status page to meet your company’s needs. StatusCast enables custom status page views, which provides each end user a unique view of services and components based on their specific role or audience.
By implementing a status page, you're not just solving your own communication challenges; you're providing peace of mind to the entire organization. Your proactive approach to downtime management elevates the credibility of the IT department in the eyes of your colleagues.
The days of drowning in a sea of "Are you down?" messages during IT disruptions are over. By embracing StatusCast's approach to incident management and implementing a status page, you can transform the way your team handles downtime. Proactive communication and transparency will not only protect your team's normal business operations, but also position you as the office hero who everyone can count on in the face of IT challenges. Embrace the power of StatusCast, and become the IT superhero your office deserves.
When IT systems falter, the ramifications extend far beyond the IT department, rippling through the entire organization. The complex web of digital systems and dependencies that undergird core functions of modern businesses are such that an interruption in one area can lead to complications across the board. This intricate interplay between technology and business that today's enterprises are built on underscores the importance of robust ITSM solutions that can mitigate outages at every layer of the stack. Incidents can strike anywhere, and their damage radius is often more vast than most expect. Organizations incur many immediate and long term consequences that are often overlooked by their IT teams who are solely fixated on uptime. There are many second-order effects that can cause IT outages to cascade into business failures, many of which we will cover in this blog; For a comprehensive approach to mitigate these effects, check out our recent blog A New Approach To Incident Management.

The immediate consequence of an IT outage is a visible halt in employee productivity, as systems that facilitate daily operations become unavailable. The cost to productivity that downtime causes is more than just the hours lost; it is also the opportunity costs and delays that are inflicted on normal operations. Such disruptions can erode an IT department’s trust within a company, emphasizing the need for quick resolution and transparency to minimize long-term repercussions.
A significant IT incident can bring critical processes and workflows to a standstill, affecting day-to-day activities and disrupting business continuity. The incident management cost associated with diagnosing and rectifying such breakdowns can be considerable, straining company resources and diverting focus from core processes that a business depends on. This operational paralysis not only affects immediate tasks but also causes a ripple effect, leading to a backlog of work that can impact business operations long after the initial outage.
The impact of IT downtime extends to the customer experience, where service interruptions can lead to frustration and uncertainty. The cost of IT incidents thus includes not only direct financial losses but also potential long-term damage to a company’s reputation. Ensuring rapid restoration of services is paramount to maintaining customer loyalty and trust.
The direct financial impact of IT outages is significant, with revenue losses from halted operations and lost business compounded by the additional resources expended during recovery efforts. This underscores the importance of preventive measures and robust incident management to mitigate financial strain on the organization.
IT outages increase stress and frustration among employees, who find themselves unable to perform their roles effectively. This situation affects morale and job satisfaction, underscoring the importance of transparent communication and rapid, efficient incident resolution.
The recovery process itself can uncover deep-seated vulnerabilities within IT systems, necessitating not only technical repairs but also potential upgrades or complete overhauls of existing infrastructure. This phase may expose the organization to additional financial burdens, including the expense of emergency response teams, overtime pay for IT staff, and the cost of implementing new security measures to prevent future incidents. Moreover, the intricacies of data recovery efforts and the necessity to comply with regulatory standards introduce further challenges, compounding the overall cost of returning to normal operations.
Downtime also poses a risk to data integrity and security, exposing the company to potential breaches and legal implications. Ensuring data protection during and after an outage is critical to safeguarding company assets and maintaining compliance with regulatory standards.
IT outages are more than technical glitches that can be reduced to the amount of downtime and speed to recovery; they represent a potential threat to every aspect of a company's operations. Addressing these challenges requires proactive measures, including a comprehensive incident management suite, and effective and transparent incident communication with a status page. By prioritizing these approaches, businesses can maintain continuity and thrive in the face of IT disruptions, ensuring their operations are resilient to the cascade of system failures that incidents normally represent.
In the realm of IT, incidents are inevitable. However, the true test of an organization's resilience lies in its ability to mitigate the impact of these incidents. Traditional incident management focused mainly on reducing downtime, but as we evolve in our approach, it's become evident that minimizing the damage and costs incurred during downtime is equally crucial. StatusCast aims to reduce not only the hours of downtime but also the cost per downtime hour, which means focusing on minimizing lost employee productivity, one of the most significant costs of IT incidents.
Minimizing the impact of IT incidents is essential for ensuring business continuity, safeguarding company reputation, and reducing financial losses. In the modern work environment, characterized by widespread remote work, the significance of effective incident communication cannot be overstressed. The complex web of dependencies on third-party services in modern tech organizations introduces an additional layer of complexity, where a failure in one service could potentially cascade into widespread disruption for your own business. Leveraging an automated incident communication system is key to supporting a distributed workforce, ensuring all teams are well-informed and able to adapt in the face of outages, enabling them to implement contingencies and stay productive.

Setting your IT team up for success means to start with a strategy and system that places the fundamental focus on corporate assets instead of on incidents themselves. Every organization has certain assets and services that are indispensable to its operations. Identifying these is the cornerstone of creating an effective crisis plan to safeguard them from the impacts of IT incidents. Understanding the dependencies and significance of these systems helps in prioritizing resources and efforts during an emergency.
A comprehensive risk assessment involves evaluating potential threats and vulnerabilities that could lead to IT incidents. Proactively assessing these risks, and routinely updating this assessment, allows businesses to prepare more effectively for specific scenarios that might arise, ensuring readiness for various types of incidents. An efficient incident response plan is essential. It should outline the key roles, responsible personnel, and procedures to follow to contain, mitigate, and recover from an IT incident. All of these critical incident response tasks should be mapped to an ITSM system that supports these tasks. This plan serves as a strategic roadmap for swift and decisive action in the face of disruptions.
Transparent and regular communication with stakeholders, including employees, customers, and partners, is paramount during an IT incident. A status page serves as an ideal platform for this purpose, offering real-time updates and maintaining transparency. StatusCast, recognized for its robust services in large enterprises and SaaS companies, provides an efficient channel to keep all stakeholders informed.
Incorporating insights from our article, A New Approach To Incident Management, StatusCast’s methodology places a strong emphasis on reducing lost productivity and the overall cost of downtime. Our approach is centered around keeping employees informed about the status of critical services they rely on, as well as reducing the complexities of dependencies, APM & Observability tools, and root causes of the incidents for the IT team. This strategy not only aids in reducing downtime but also in minimizing the disruption and costs incurred during downtime. Below is a high level outline of our incident management approach:
At the heart of StatusCast's incident management strategy is a blend of pivotal principles aimed at keeping employees productive and IT proactive in the face of outages. The objective of an organization when systems go down should be to maintain operational continuity and employ a strategic response during IT incidents. Stakeholder communication is central to our approach, ensuring that not just the IT team, but the entire workforce remains active and engaged during disruptions. This proactive communication strategy is akin to navigating through a potential traffic jam with timely updates, steering clear of operational disruptions and maintaining workflow continuity. Complementing this, our Asset First Approach shifts the focus from just incidents to a broader perspective that includes the vital importance of service components. This approach offers a more holistic view of how incidents affect an organization, enabling end-users to better understand and adapt to these disruptions.
Further enhancing our incident management capabilities, we integrate seamlessly with APM and monitoring systems. This integration is crucial in large enterprises where multiple systems, often operating in silos, can create a complex web of alerts and notifications. Our solution centralizes these communications, filtering out irrelevant noise and focusing on actionable alerts. We also incorporate runbooks in our ITSM system, which are vital for streamlining incident management. These runbooks facilitate the creation of content templates, administrative tasks, and workflows, which ease the burden on IT professionals. Additionally, our extensive RCA (Root Cause Analysis) database and comprehensive reporting provide valuable insights for strategic planning. This approach, coupled with our efficient management of shifts, on-call assignments, and escalations, ensures that the right personnel are alerted and involved in timely resolution, further reducing downtime and its associated costs.
The essence of effective incident management lies in recognizing the need to minimize lost resources and productivity during IT incidents, as well as reducing total downtime. StatusCast's approach, with its focus on continuous productivity and strategic communication, provides a robust framework to support organizations in navigating the complexities of modern IT environments. Our comprehensive incident management, robust status pages, and strategic integrations work together to ensure resilience and operational integrity, safeguarding businesses against the unpredictable nature of IT incidents.
In recent years, IT departments have faced the challenge of adapting to an evolving landscape of demands. While the primary focus of traditional incident management solutions has been to reduce downtime, it's become clear that just reducing the amount of downtime isn’t sufficient. To truly mitigate the total impact of downtime, there must be a focus on reducing the damage and costs that accumulate while you are down. Downtime cannot be entirely avoided, so when it happens, ensure that it is not debilitating for your entire organization. One of the greatest such costs of downtime turns out to be lost employee productivity. If IT doesn’t have the tools to adequately prepare their organization for the chaos of outages, and employees are left in the dark with no recourse, unable to perform their normal tasks, then the cost of every minute of downtime skyrockets. Effective Incident Management in 2024 is not just about reducing the amount of downtime, but reducing the damage that occurs while you are down.
Given the ubiquity of remote work, effective incident communication is more important than ever. A robust platform providing automated incident response and communication has become mission critical in supporting a distributed workforce. Keeping teams optimally informed and adequately prepared is necessary to mitigate an overflow of support requests and keep employees on task when outages occur. Businesses thrive during outages when they prioritize incident communication, to keep employees informed when disruptions affect their operations, and with ITSM automation, which saves IT from anything not directly related to rapidly resolving the incident.
Enterprises are accustomed to how severe hourly downtime costs can be. ITIC reports that over 90% of mid to large sized enterprises average downtime costs of over $300,000 per hour, with 44% reporting costs exceeding $1,000,000 per hour. However, the second order effects of outages have become more apparent to IT departments in recent years. Carbonite found that for 57% of IT departments, incidents often require 100% manpower and other resources for their duration, pulling teams away from other critical functions. This led 46% of organizations to report that loss of productivity was the biggest cost they faced in the wake of an incident.
To address this challenge, a new paradigm of IT incident management has emerged that puts the spotlight on reducing lost productivity, ensuring that not only are hours of downtime reduced, but the cost per hour down is reduced. This approach is centered on the idea that by keeping employees informed of the status, dependencies and root cause of outages, IT teams can protect organizational integrity and minimize the disruption caused by system failures. Enterprise IT departments have been looking to StatusCast to reinforce their incident response because of our unique approach to reducing downtime costs. StatusCast keeps employees updated with the status of affected services, with maximum depth and specificity of reporting, in order to efficiently resolve downtime while minimizing downtime cost.
One of the key features of our incident management solution is its ability to send targeted, personalized notifications to employees based on their role and the components/services they depend on. This ensures that employees only receive the information that is most relevant to them, helping to reduce noise and avoid information overload. Additionally, StatusCast empowers IT teams to save valuable time on incident notifications and updates by automating the process with AI-Powered Smart Incident Messaging, which crafts notifications with specific knowledge of the incident at hand and leverages your communication style from past messaging. These notifications are then distributed across multiple-channels, including Slack, Teams, Email, SMS and via push notifications; ensuring that employees are kept in the loop whenever disruptions affect services they depend on.
Leaning into ITSM automation is a key aspect of StatusCast's incident management approach. Whether it’s automatically crafting incident notifications, or managing complex integrations with Observability and APM tools, StatusCast ensures that IT teams are freed up to focus all their attention on solely expediting incident resolution.
StatusCast's unique approach marks the beginning of a new frontier in the world of Incident Management. Given the increasing reliance on remote work, it has only become more important for off-site IT teams to have a robust, automated incident solution. By prioritizing incident communication and leveraging automation, IT teams can keep employees optimally informed and maximally productive during outages, helping to effectively reduce the costs of downtime.
Discover How Our Incident Management Can Help Your Business Thrive
Book a Demo or Start Your Free Trial Today

Stakeholder Communication
Effective stakeholder communication is pivotal in our approach to incident management. When incidents arise, it's not only the IT team that faces a productivity slump; proactive communication is key to keeping the entire workforce active and engaged. Consider this analogous to avoiding a traffic jam upon receiving timely updates - it's about steering clear of disruptions and maintaining workflow continuity.
Asset First Approach
Our 'Asset First' approach marks a departure from traditional ITSM models. Rather than just focusing on incidents, we emphasize the importance of service components. This approach provides a clearer picture of how incidents affect the organization as a whole, enabling end-users to better understand and adapt to these disruptions.
Tie Into All Your APM and Monitoring
Integration with application monitoring systems is also a cornerstone of our strategy. In large enterprises, the multitude of systems, often operating in silos, can create a cacophony of alerts and notifications. Our solution centralizes these communications, filtering out irrelevant noise and focusing on what's truly actionable.
Runbooks
Runbooks are another essential element. While each incident might be unique, the underlying processes often aren't. Our ITSM system allows the creation of content templates, administrative tasks, and incident workflows. All of these assist IT professionals, easing their burden and streamlining the incident management process.
RCA Database
Extensive RCA (Root Cause Analysis) reporting and functionality is vital for truly proactive incident management. Instead of treating RCA as a mere follow-up to incidents, we categorize and report on them. This enables trend analysis and deeper insights, such as comparing hardware failures against third-party service outages over time, offering valuable data for strategic planning.
Shifts, On-call Assignments, Escalations
The complexity of IT departments, with their varied teams, shifts, and managerial structures, requires a flexible ITSM solution. Our system is designed to accommodate different team structures and responsibilities, ensuring efficient management of shifts, on-call assignments, and escalations. This structure further reduces informational noise and enhances focus on critical issues.
Executive Insight and Reporting
Incident Management reporting is an area where many ITSM solutions fall short. Our solution goes beyond basic incident reporting, offering comprehensive analytics on incidents, components, subscribers, SLAs, and more. This level of reporting provides valuable insights for stakeholders, enabling informed decision-making and strategic planning.
The essence of effective incident management lies in recognizing that your sole focus cannot simply be on reducing the amount of downtime, but in reducing the cost and damage while you are down. This holistic approach ensures that when inevitable disruptions occur, their toll on the organization's productivity and resources is significantly minimized.
At the heart of this refined strategy is the understanding that minimizing lost resources and productivity is the proper objective function for any organization striving for a tangible reduction in downtime costs. StatusCast embodies this philosophy, offering a suite of features designed to not just lessen downtime but also to alleviate its consequences. Through targeted communication, comprehensive incident management, robust status pages and strategic integrations, we provide a robust framework that supports continuous productivity, even in the face of IT challenges.
In embracing this comprehensive approach, organizations can navigate the complexities of modern IT environments more effectively, ensuring resilience, maintaining operational integrity, and ultimately, safeguarding their bottom line against the unpredictable nature of IT incidents.
We are thrilled to introduce the latest innovation from StatusCast: our groundbreaking mobile status page application, which will be available on both Android and iOS platforms. This launch marks a significant milestone in the evolution of status page accessibility, offering unparalleled convenience and functionality to your power users, the subscribers.

The StatusCast mobile app is designed to provide real-time status updates directly to your end users. With this app, your users can:
Customize Their Dashboard: Seamlessly track and ingest data from various SaaS status pages we monitor. Create a personalized dashboard combining third-party pages with the ones they already subscribe to.
Access Private Status Pages: Securely log in and view status data for any private status page they have access to.
Stay Notified Instantly: Set up push notifications to receive immediate alerts when your status pages have important updates.
For Administrators: Simplified Incident Management on the Go. While our primary focus with our mobile release is enhancing the subscriber experience, we haven't forgotten about the administrators. The mobile app also includes a simplified version of our admin dashboard. This feature allows admins to quickly create and manage incidents from their mobile devices, offering a streamlined and efficient way to maintain communications.
What sets the StatusCast mobile app apart is its unique focus on the subscriber experience. While many incident management and observability vendors offer mobile applications, these are typically geared towards administrators. Our app breaks new ground by being subscriber-centric, providing a tailored experience for end-users to stay informed and connected.
In addition to our mobile offerings, we're excited to announce the launch of a Windows Desktop version of our app. This version mirrors the mobile app's functionality, providing real-time status updates and notifications directly on your desktop.
Our new release will be available on IOS, Android and Windows in the beginning of Q1 2024. We invite you to experience this new front of the status page industry. Give your valued users a new level of convenience and engagement with your status pages.
StatusCast the leading provider of status page solutions, offering Public Status Pages, Private Status Pages, and an all-encompassing Incident Management suite. These products come with varied pricing options tailored to meet the specific needs of different businesses. The aim of this guide is to help you seamlessly navigate these options and choose the best StatusCast pricing plan for your needs.
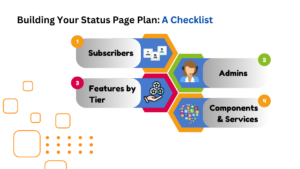
When deliberating on the ideal StatusCast pricing, keep these pivotal points in mind:
Number of Subscribers: Consider how many subscribers your status page will need to support. Remember, the function and cost of subscribers vary between public and private pages.
Features: Prioritize which features are critical for your business to maintain continuity and flawless operation during outages. Does your approach to incident response encompass a complex array of systems across a multi-national organization? Then you may need to ensure that your package includes a significant amount of automation (codeless integrations and rulesets), component reporting and admins.
Budget: Establish your budget for a status page service. Analyze your organization’s hourly and annual downtime costs to grasp the value that our status page could provide in mitigating these expenses, and weigh that upside against the cost of your preferred status page plan.
Selecting the right StatusCast pricing entails a nuanced understanding of your organization's requirements:
Subscribers: For public status pages, it’s crucial for end-users to subscribe for incident notifications and updates. While for private status pages, ‘subscribers’ are much more engaged with your status page, as employees or SaaS customers who directly access the page.
Admins: Determine the number of individuals you want to maintain the account, handle incidents, and manage configurations.
Features by Tier: Public status page clients often focus on the CNAME offering in our Corporate plan. Both public & private status pages also unlock full branding and design at this level. Most who choose Enterprise do so due to a heightened need for more admins or subscribers. Beyond these, Enterprise also provides more extensive reports. For a comprehensive comparison of every feature available in each pricing plan, scroll down on our pricing page.
Components & Services: Components and services, as well as component levels (depth of reporting), also scale up with each plan. This is a common upgrade for many clients who successfully integrate our status page into their incident response process, and look to showcase more of their organization’s on their status page.
Considering these key decision points, let’s compare the various plans:
The Public Status Page offerings kick off with the Starter plan at $50/mo. Next, the SMB plan, priced at $99/mo, provides for up to 2,000 subscribers and includes 25 services and components. It also introduces 2 Beacons (codeless integrations) allowing for seamless connectivity. However, the Corporate plan is where most organizations find their sweet spot. Priced at $299/mo, Corporate caters to a larger audience with 5,000 subscribers, 35 services and components, and boosts integration capabilities with 10 Beacons. Enterprise is next, providing first-class support for large enterprises to support 10,000 subscribers, 100 services and components with 5 levels of reporting depth, and 30 beacons and 10 rules per beacon for an unmatched level of integration. These plans not only provide scalability but also a range of features tailored for varying business needs.
When it comes to Private Status Pages, the journey begins at $99/mo with the Starter plan. But for businesses seeking more depth and flexibility, the SMB and Corporate tiers offer compelling features. The SMB plan costs $299/mo, designed for up to 300 employee subscribers, featuring 25 services and components, complemented by 2 Beacons for smooth integration. For organizations requiring an even broader range, the Corporate plan at $499/mo is optimal, supporting up to 500 employee subscribers, 35 services and components, and enriched with 10 Beacons. Enterprise is a custom plan that can support 10 administrators, 1000 subscribers (employees) and the same amount of components and beacons as the public enterprise plan.
StatusCast's Incident Management software isn't just an afterthought; it's a core product offering. Our Incident Management suite is an end to end solution that equips your organization with the tools to proactively mitigate service outages and expedite incident resolution when downtime does occur. Combat incidents before they occur with our Root Cause Analysis reporting, leverage enhanced incident management automation with our AI-Powered Smart Incident Messaging, and ensure effective workflows with intelligent escalations that inform and task the right team members when things go down. Our incident management pricing starts at a modest $4/mo per team member and progresses based on feature depth, reaching $29/mo for the Enterprise tier.
Your business needs might evolve. Thankfully, StatusCast provides flexibility, enabling you to switch between plans to ensure you’re always availing optimal value.
Deciphering the right pricing plan is crucial for gaining maximum value from StatusCast’s status page software and incident management tool. Your choice should reflect your organization's needs and, importantly, your budget considerations. As downtime can prove costly, selecting the right StatusCast plan can be an instrumental step in mitigating potential losses. Make an informed decision, and remember, StatusCast is here to support your organization's uninterrupted operations.
© Copyright StatusCast 2022 | Terms & Conditions | Privacy Policy

