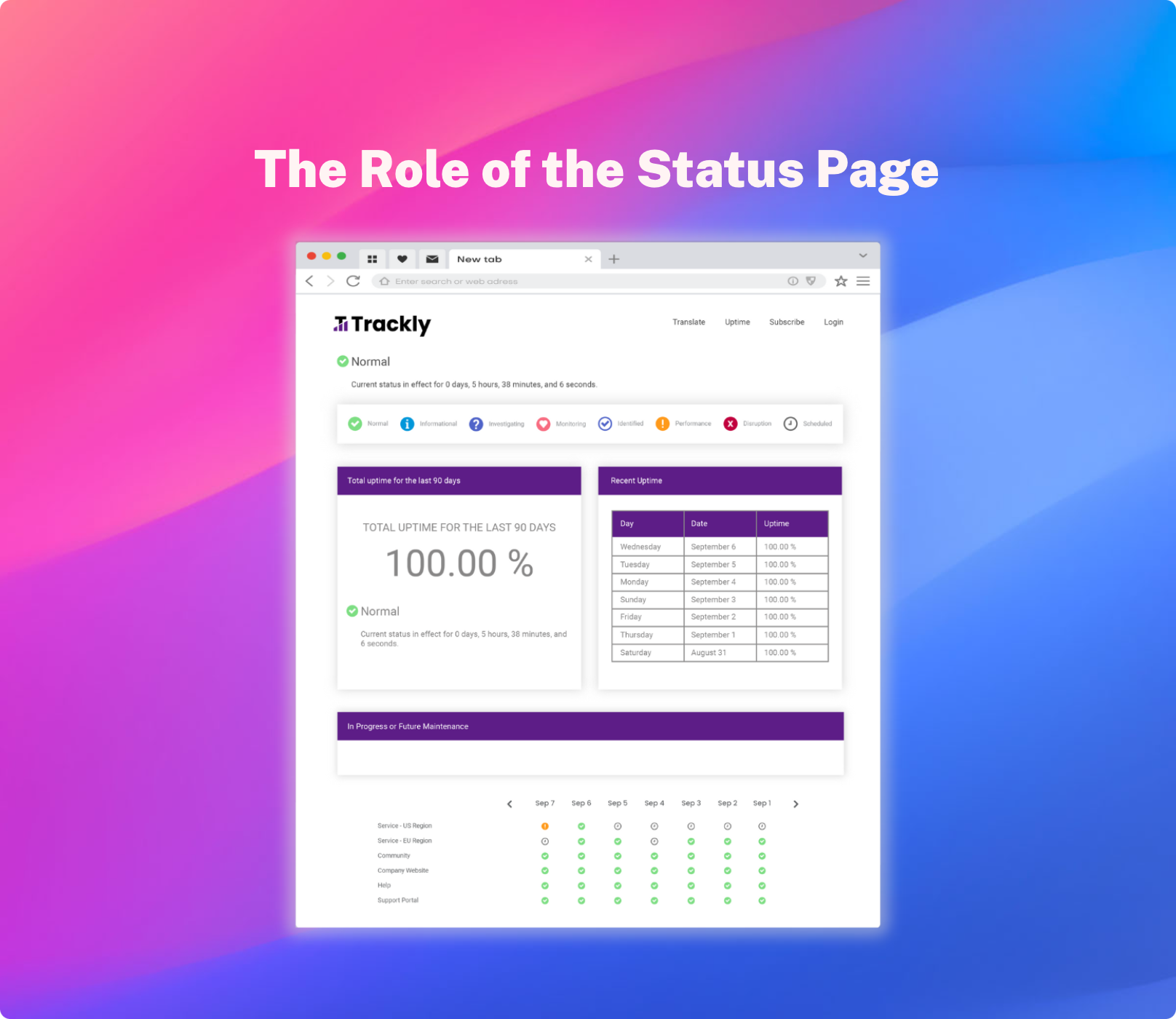
Servers are down. Employees are scrambling. Customers are upset. The pressure is on.
When internal operations are in disarray, and your business is experiencing a service outage, the last thing you need to worry about is the reliability of your incident communication solution. Keeping users informed when services are down is mission-critical, in order to prevent a flood of support requests, which compound the effects of the incident, straining employee productivity and bandwidth.
A public or private status page is often the only way to communicate with the outside world during an outage, providing the last line of defense between you and complete chaos. Choosing a small SaaS provider of public-only status pages may seem like a cost-effective option, but in reality it should be the last place you should look to cut costs, as this opens your business up to various failure points. Here are the top five reasons why you should avoid small providers and opt for an established vendor with a proven track record.
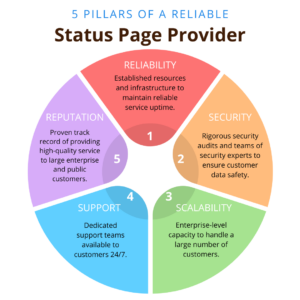
Small providers may not have the resources or infrastructure to ensure that their service is always up and running. Established vendors, on the other hand, have invested in the necessary hardware and software to provide a reliable service. They also offer reliable SLA’s that protect your investment.
Small providers may not have the expertise or resources to ensure that their service is secure. Established vendors have teams of security experts who work to ensure that customer data is safe and secure. Make sure your status page vendor has an independent security audit such as SOC-II Type 2
Small providers may not have the resources or technology to handle a large number of customers. Established vendors have the infrastructure and expertise to scale their service to meet the needs of large enterprise customers.
Small providers may not have a dedicated support team to help customers with any issues or questions they may have. Established vendors have teams of support experts who are available 24/7 to assist customers. When your servers go down at 2:30am Saturday night, make sure your status page provider will be there … just in case.
Small providers may not have a strong reputation in the industry. Established vendors have a proven track record of providing a high-quality service to many large enterprise and public customers. Go to the vendor's customer page. Do you recognize any of those brands? Consider finding a vendor who has successfully served big recognizable names.
When your business is experiencing an outage, the last thing you need to worry about is the reliability of your status page, the centerpiece of a strong incident response strategy. Choosing a small SaaS provider of public status pages may seem like a cost-effective option, but it comes with several risks that can negatively impact your business. To ensure that your status page is robust and resilient to the uncertainty and chaos of service outages, you should prioritize established vendors who have been tried and trusted by large enterprises in your search for an effective incident communication solution.
To understand the impact that stovepipes have on incident response, one need look no further than the 9/11 terrorist attacks that occurred in the United States. The CIA, DoD, and FBI all knew about the Al Qaeda terror threats before the planes hit the World Trade Center, but the 9/11 Commission found that a lack of data and intelligence sharing among the agencies limited each agency’s understanding of the looming terrorist threat; thereby, limiting their incident response. This lack of information sharing made it difficult for intelligence leaders to "connect the dots" and thwart the attack.
Thankfully, most IT stovepipe scenarios do not lead to such dire consequences; however, they do impact incident response when your IT systems go down. Wikipedia defines IT stovepipes as "systems procured and developed to solve a specific problem, characterized by a limited focus and functionality, and containing data that cannot be easily shared with other systems."
These singularly focused, non-integrated systems make the lives of IT help desk support personnel more time-consuming, more expensive and more frustrating (for both the support team and business stakeholders outside of the IT organization).
Employees and customers increasingly demand more transparency from corporate IT support teams, making stovepiped systems an "ugly" word with IT leaders. One of the best ways to meet the demand for more transparency is to invest in a Corporate Status Page.
A corporate Status Page provides a unified portal from which your IT help desk staff can assess all problems and planned outages across your IT ecosystem. Having a unified view provides your IT help desk team with holistic insight into the status of your enterprise IT systems & software. This all-encompassing perspective is invaluable when communicating with employees and customers about outages and planned maintenance.
By providing proactive incident management and planned maintenance communications, a corporate Status Page helps boost stakeholder trust, which in-turn leads to better customer and employee satisfaction.
In addition, by having all IT notifications feed into a single Status Page, you boost your IT help desk team’s productivity and reduce your IT support costs.
When looking to bust your incident response silos, you must ensure the Status Page solution you select meets the following requirements:
Allows for end-user-friendly, customizable pages and messages to provide stakeholders information they can use and understand versus "tech-speak"
If your business is plagued by silos in your IT incident management approach, you should consider a corporate Status Page. You’ll not only boost IT help desk team productivity, but also you’ll improve IT transparency, which has been proven to improve both employee and customer satisfaction.
If 2020 taught us anything, it is that a corporate Status Page is an IT ‘must have.’ With this one solution, IT leaders are able to address new challenges of remote work teams, as well as traditional issues — like high IT support costs, employee productivity, stakeholder transparency and IT team efficiency.
2020 was a year marked by the ‘virtualization’ of nearly every aspect of life. From doctor’s appointments to happy hours, we quickly moved live events to online environments like Zoom and Google Hangouts. Never was this truer than for corporate teams who were used to working in office buildings.
As professional teams transitioned to virtual work, companies faced a plethora of new challenges. Not only did they have to setup virtual work environments with the right tools for the job; but also, they had to determine how to keep their employees engaged, communicate with teams effectively and ensure a high level of employee productivity with remote work.
These new remote work challenges, along with traditional issues that weigh heavy on IT leaders’ minds — are improved with a corporate Status Page solution.
Reason #1
Reduced IT Help Desk Support Costs
If you have ever worked in a corporate environment, you surely have experienced the following scenario: You log into your laptop to start your day and find that Office 365 is not working. You, along with hundreds of your co-workers, call your IT help desk to report the problem and suddenly your IT support team is overloaded with too many support requests for the same issue.
IT support tickets cost on average $104. When you add this expense to the opportunity cost of employees and IT teams being less productive, you can see how much IT support tickets impact the bottom line of the business. By implementing a corporate Status Page, organizations can reduce inbound help desk costs by preventing the rise in incidents from happening in the first place.
IT leaders are able to save themselves the headache and cost that a surge in help desk requests creates by using proactive communication as one of the outage communication best practices and planned maintenance to employees as well as customers.
Reason #2
Higher Employee Productivity
Employee productivity is always a concern — whether your teams are in-office or working remotely. According to the 2015 HIS Markit study, North American companies lose up to $700 billion a year related to IT outages. This includes a 78% loss in employee productivity.
The total revenue loss from employees’ inability to access core systems during outages marks only the start of the negative domino effect. If the impacted employees also play customer-facing roles, the outage can impact customer service, sales, customer support and other customer-oriented business functions.
To protect against outages and resolve them quickly, many corporations have turned to corporate Status Pages to provide proactive and integrated incident management communications. By integrating all IT notifications into one interface and being proactive in sharing information with both internal and external stakeholders, IT teams are freed up from the flood of calls and emails they receive without a corporate Status Page. This ‘free’ time can be applied to resolving the problem at hand versus recording yet another ticket for the same issue.
Another way a corporate status boosts employee productivity is in the area of communicating planned maintenance information. By knowing in advance when maintenance will be performed, employees can better plan their workday, focusing on off-line tasks during the time when systems are unavailable. This ability to adjust their workday according to system availability means teams are using their time more wisely and are thus being more productive.
Reason #3
Greater IT Transparency
According to business.com, companies that embrace transparency as a core business value find that it leads to consumer trust, loyalty and business success. And why not? Transparency fosters trust, and trust is important for the health of every relationship – both personal and professional.
According to the Label Insight Transparency ROI Study, at least two-thirds of consumers would spend more if it meant buying from a transparent company and 94 percent rank transparency as the greatest factor in brand loyalty. In addition, Harvard Business Review notes that obtaining a new customer is anywhere from five to 25x more expensive than retaining an existing one.
Company transparency is also of utmost importance to employees. In fact, Forbes notes that employees indicate that transparency is the number-one factor in determining employee workplace happiness.
A corporate Status Page goes a long way toward providing IT transparency to both internal and external stakeholders. By providing proactive incident management and planned maintenance communications, a corporate Status Page helps boost stakeholder trust, which in-turn leads to better customer and employee satisfaction.
Reason #4
Improved IT Team Efficiency
By implementing a corporate Status Page, you not only free up your IT team to focus on higher value tasks, but, assuming your Status Page supports unified communication, you are also making your IT team more efficient in performing their tasks. Instead of spending considerable time using multiple notification interfaces across myriad IT apps and systems, with a corporate Status Page, IT teams use a dashboard that integrates all incident management notifications into one customizable dashboard.
Modern status page providers are able to fully integrate with all your external third party SaaS products. They can ingest their status in real-time and proactively forward new incidents to your IT team or directly to your employees. Imagine the time saved by a system that automatically notifies your employees of the next Office365 or AWS outage.
Reason # 5
Remote Work Benefits
SocialChorus and Pulse recently “surveyed 100 global enterprise IT leaders to uncover how they are prioritizing employee engagement and communications improvements…and the top technology features that would help them derive greater ROI from their digital employee experience investments.” 93% of IT leaders who participated in the survey said that employee engagement and communication is a higher priority initiative in 2020 as a result of the rise in remote work. In addition, 49% of these leaders agree they would “be able to better calculate ROI…and boost productivity with a unified view of analytics across all tools and platforms.”
A corporate Status Page addresses these IT leaders’ needs with one unified view of all incident management notifications. IT teams as well as other employees can be more efficient and productive, IT leaders are better able to perform ROI analyses and employee engagement and communication get a boost — all because of a corporate Status Page.
As 2020 draws to a close and we look toward a new year, IT leaders are advised to consider investing in a corporate Status Page. With this one solution, IT teams are able to do their best work while at the same time reducing IT support costs, boosting employee productivity, improving IT transparency and addressing the unique needs of remote workers.
Founded in 2013, StatusCast is a unified communications cloud-based platform that allows IT to easily communicate status and scheduled maintenance messages to its end-users with a powerful application status page. Want to see how a status page can benefit your business? Start your 14-day free trial or schedule a demo today!
If you care about the uptime status of your website or SaaS application, there are two really great pieces of content shared last month that you should look into. One is an article on continuous testing from Parasoft Corporation, featured on DZone. The other is a recorded presentation on Application Performance Monitoring (APM) by Expected Behavior, from the Full Stack Toronto conference.
The DZone article covers shifting from an automated testing mindset to continuous testing. It argues that this is essential for groups taking a DevOps approach to software deployment. It also advocates for changing the essential pre-deployment question from “are we done testing?” to “does this candidate for release have an acceptable level of business risk?”
It also presents some excellent questions, such as:
“Is there a clear workflow for prioritizing defects vs. business risks and addressing the most critical ones first? And for each defect that warrants fixing, is there a process for exposing all similar defects that might already have been introduced, as well as preventing this same problem from recurring in the future? This is where the difference between automated and continuous becomes evident.”
Maintaining a high SaaS application uptime will only increase in difficulty if you do not have such a process in place.
Expected Behavior’s Full Stack conference presentation draws parallels between unit testing and application monitoring to underscore why APM is worth the investment. Though APM systems may seem “too expensive” to those not already using them expertly, they will pay off for companies in the long run—just as unit testing was initially approached with trepidation but now has become standard.
As the complexity of software increases, the importance of detecting and documenting performance issues increases. That said, you don’t want to rigorously test everything – or you’ll get buried in data. It can be helpful to conceptualize what you need to monitor with an APM in the same way you’d conceptualize what you’d want to unit test. This approach can help you focus on measuring only what really matters to your software’s performance- such as interfaces between components.
The presenter from Expected Behavior, Nathan Acuff, offered this fantastic advice during the presentation as well:
While your software’s uptime performance may be fine, there are often components that rely upon external partners or providers- and when these suffer slowness or outright downtime, your customers are still going to hold you accountable for the problem.
By offering regular updates to your end-users about the status of the various components that integrate with your solution or that your solution relies upon, you establish a baseline of trust in your product and in your organization’s management of the suite of tools that power your solution. It’s much easier for users to understand the context in which your product operates if you’ve proactively told them about it from the beginning, rather than only beginning to address it after they initiate the conversation with you unhappily.
Content marketing is all about adding value to your communications with customers and prospects. Value might take the form of information or entertainment or something else (you can see one example below). We’ve already talked on this blog about using a software status page to support SaaS content marketing, but uptime status alerts shed light on a B2B content marketing truth you might otherwise overlook.
Last month, Tom Kaneshige shared an article on CIO magazine about what B2B and B2C marketing teams can learn from one another. Not surprisingly, the B2B folks have really refined the production of educational content, e.g. whitepapers, commissioned research, etc. (which B2C marketers might benefit from, as consumers increasingly research and compare before buying).
More interestingly, he believes B2B folks can learn from the practiced B2C marketers in how to create inspirational or emotional content.
There’s a lot of merit to this line of thinking, but the timing of it (i.e. where in the customer journey) is important. Additionally, you have to be careful how far down the “inspirational” path you take it—going so far as Just Do It, for instance, is too disconnected from the core value your marketing needs to explicitly convey about your product.
Unless you’ve got a really transformative product (see the oft-cited Slack), you’re going to have a hard time spinning your offering as the innovative lifehack your prospects didn’t even know they needed.
That’s not to say that you should pack up shop if you’re not the next Slack- only that you should position yourself more appropriately. More on this in a moment.
Furthermore, end users are not decision-makers. Once your product is already implemented, then end-user marketing is relevant (and arguably instrumental to retention), but until the sale is made, their excitement about your product is largely secondary to the bottom-line.
So what’s a B2B marketer to do?
Prior to the moment of sale, you need to focus your messaging on an ideal or set of ideals your product can help your customers achieve.
In the case of StatusCast, that’s transparency, trust and reputation. We are diligent in our marketing materials to remind prospects that uptime status isn’t just a consideration for SLA agreements but a matter of relationship-building. It’s something that impacts the bottom-line, but it’s also an idea you can get behind.
After the moment of sale, you need to begin messaging to end-users, developing the necessary relationship with them that will help make your solution “stickier” (i.e. reduce the number of reasons for decision-makers to consider alternatives).
Though it’s poor form I’ll cite StatusCast again- our product is built to help other SaaS companies communicate with their end users, so this is easier for us than most. Once a customer is live, each end-user is able to subscribe to downtime communication alerts via their respective preferred communication methods (e.g. email, tweet, SMS/text message, etc). This makes engagement easy, as end-users have self-selected the best way for you to reach them.
Additionally, our primary users are going to be IT or Marketing staff, who will use StatusCast to develop pre-made messages to provide alerts and updates on uptime status (e.g. scheduled maintenance, unplanned performance disruptions, etc.) to their end-users. In our marketing materials, we talk about how drag-and-drop easy it is to set-up a software status page with StatusCast and remind our users how beneficial it is to complete this during a period of calm rather than trying to make it all happen during a period of crisis (i.e. while your application is experiencing downtime).
In so doing, we connect the positive and negative experiences our end-users are likely to encounter and/or can easily relate to, with the ideal and non-ideal usage of our software.
What we haven’t gotten good at yet (and perhaps should) is taking this one step further and promoting the Nike-esque ideal at the end-user level. We don’t really have a slogan or motto to inspire our end-users to greatness.
One last note about engaging end-users on an emotional rather than educational level. StatusCast again has an “in” here, as the software status page we provide is most relevant when end-users are likely to be in an emotionally-charged state (your product is unavailable or not performing the way it’s expected to).
If you can determine when and in what way your users are likely to be more receptive to emotional or experience-oriented content, you can get more mileage out of Tom Kaneshige’s content marketing advice.
Most SaaS companies will promise 99% uptime, many will even promise 99.9% uptime. However, on average companies continue to experience 12 incidents of unplanned application downtime every year, each of which lasts 1-2 hours if it’s a critical failure and gets immediate attention, or more than 3 hours if it’s non-critical.
To be clear, 99.9% uptime still allows for more than 8 hours of downtime each year, but usually this is meant to cover scheduled maintenance, stress testing, disaster recovery testing, etc. If you’re following the arithmetic you’ve already figured out that on average companies are subject to as “little” as 12 and as much as 40+ hours of application outages each year. Recall scheduled maintenance would be downtime on top of this unplanned outage time. As such, many SaaS companies face uncomfortable contract conversations regarding violations of their Service Level Agreements (SLAs). Often the expectation is set at 99.9% in the SLA, and as such often performance fails to meet expectations.
In this situation, the right move is to set expectations with the customer appropriately from the start – otherwise at best you’ll lose upsell opportunities (see customer lifetime value below) and at worst you’ll lose customers altogether (see churn below).
Recurring revenue is usually calculated monthly (MRR). Obviously you’d like it to grow as much as possible, but for frame of reference- the top-performing SaaS companies achieve $50 million dollars in annual revenue by their 8th year. This is a relatively new trend, as previously it had taken well over 10 years to hit this mark. It’s also worth noting that once they hit this point, some of these top-performing company’s revenues continued to roughly double year over year, which may or may not be a realistic place to set the bar for your organization.
Again I would direct you to a recent post on how using an application performance management system to help you handle SaaS application uptime can help protect your recurring revenue (the key word is “recurring”).
Customer lifetime value (CLV) takes MRR and extends it over the anticipated duration that a customer will continue doing business with your company (i.e. how long that recurring revenue will be recurring). Ideally, this will be many, many years, but realistically you won’t be able to capture all of that revenue for every customer. Additionally, the amount itself will fluctuate as customers downgrade their investment with you or as sales upsells customers.
Ideally, you’ll see 14% growth in your CLV annually, but that’s difficult to attain, especially with consistency. But let’s bring things back down to Earth for a minute: fluctuations aside, how long should you expect to retain a customer for purposes of calculating lifetime value?
Churn represents the fraction of customers or revenue (depending on how you calculate it) that you lose every year/quarter/month (the interval at which you measure churn usually corresponds with the interval of your contract renewals).
Churn can be the bane of your SaaS business. Lincoln Murphy wrote a great article about the importance of being clear about how you’re calculating churn. Here’s the short version: 5% annual good, 5% monthly horrible. Once you’ve calculated your churn rate, you can more accurately determine your average CLV.
But how can you prevent churn?
Alex Bloom outlined two key points that can help mitigate churn in a recent article on the New Relic blog. In short: focus on onboarding and engagement/use of your product. But read the article for the details of how.
For more information about financial metrics (as opposed to more technological metrics like SaaS application uptime), check out this article from New Breed and this “cheat sheet” from ChartMogul. Customer Acquisition Cost (CAC) for instance, is very important. I did not cover it in this article but you’ll find information about it in both of the linked resources.
Finally, visit our homepage to learn how a hosted status page can support your efforts to reduce churn by building strong communication patterns with your customers.
While application performance monitoring is valuable for anticipating and responding to issues that threaten SaaS application uptime, it is deficient for two audiences:
1) your IT team – application performance monitoring does not proactively address issues by managing performance, it merely monitors and alerts
2) your users and your Marketing team – application performance monitoring does not address user communication at all
The first reason represents a deficiency in application performance monitoring because it demands immediate attention from IT, even to correct minor issues. The better approach here is to utilize an application performance management (APM) solution. An APM tool will include features like automatic failover, which helps to avoid application downtime by immediately redirecting activity from components experiencing performance issues to fully functional components. This frees IT to troubleshoot the issue after the fact rather than forcing the team to drop everything immediately and put out the fire the issue caused.
APM solutions are not magic, there will still be instances of downtime that require IT to go into crisis mode. The rationale behind implementing an APM is to make those instances significantly less frequent and shorter in duration. APMs empower IT to immediately identify and handle the smaller issues while providing data about those issues, which can inform IT about how to better anticipate, avoid and rapidly address bigger threats to SaaS application uptime in the future.
The second reason represents a deficiency in application performance monitoring because it does not translate service disruptions into terms your end users can understand. This is obviously a problem for your users and as a result is a problem for your Marketing team. The better approach here is to supplement your APM with a hosted status page that can provide intelligible, timely downtime communication to your users. This ensures that your users feel well-informed about issues with application performance or even application availability (in instances of application downtime). This is equally true for anticipated downtime (e.g. maintenance) as it is for unexpected issues. There are many other reasons to utilize a hosted status page, not the least of which is to take the burden of communication off of IT. You can read more about hosted status pages here.
I’ve not yet come across a study that directly connects SaaS application uptime statistics with revenue growth, though there are certainly examples of repeated instances of downtime hitting a company’s revenue hard. Much like everything else in IT, when it goes well, there’s no real conversation, but when it goes poorly, everyone has a stake in IT resolving it as quickly as possible and avoiding it more effectively in the future.
Where Marketing is concerned, however, revenue growth is dependent upon customer satisfaction – happy, referenceable customers (or customers who are actively brand advocates) are the key to explosive growth. Rather than waiting for there to be a problem, make sure every interaction your users have with your company is a positive one. Engage your Marketing team about how you might implement more user-friendly downtime communication.
On those rare occasions when Marketing reaches out to IT for product performance information, ideally your company’s 99%+ uptime is the subject of conversation (rather than instances of application downtime). However, it’s inevitable that your application will go down at some point and at that point, the conversation—from the Marketing perspective, at least—is necessarily one of communications damage control.
Application downtime crises look something like this:
To be honest, you can’t 100% prevent service disruptions. It’s unreasonable to expect that of your IT team—even giants like Facebook and Google have experienced downtime.
What you CAN prevent is the crisis part of the service disruption, and that’s where Marketing comes in to support IT. But before diving into the How, more of the Why.
Regardless of how many hundreds of thousands of dollars in reputation damages and lost customers application downtime represents (again, see stats at the end for why it would be $170k vs. $240k), it’s clear that Marketing has a stake in preventing the severe unhappiness that results from a service disruption.
Not only is it stressful and unpleasant to deal with in the thick of a crisis, but the long-term consequences to customer retention and referenceability (not to mention overall company growth and profitability) are truly painful. The solution is providing an accessible, customer-facing communications tool that promotes uptime.
There are two important priorities when effectively handling customer dissatisfaction: expectations and professionalism.
Expectations need to be understood and managed—while it’s not unheard of for customers to have unreasonable expectations, generally their expectations are reasonable given what they were told during the sales process. As such, when it comes to application downtime, setting expectations early and often is critical to minimizing costly customer dissatisfaction.
Professionalism is the level of competence and courtesy you demonstrate to your customers that conveys to them that you know what you are doing and that you care about serving them well.
By providing an application status page—the aforementioned “accessible, customer-facing communications tool”—that promotes uptime, you are managing expectations and demonstrating professionalism by:
Marketing needs to be aware of and actively promoting uptime as preparation for the infrequent but inevitable and costly instances of application downtime. An application status page that integrates automatically with your application monitoring tool (e.g. New Relic) is the easiest way to communicate with your end users and customers about uptime. Failure to communicate about uptime effectively amounts to failure to mitigate any of the hundreds of thousands of dollars in reputation damages and customer churn described in the Ponemon research report(s).
Tired of checking your website or app multiple times a day to make sure its working the way it should? Wouldn’t it be a relief if there were a service that monitored your application 24/7 and notified you the minute a disruption in uptime occurs?
If tech titans like Yahoo, Google, and Twitter can go down, you can just about guarantee that your application will experience downtime as well.
Uptime tools are becoming increasingly popular and are quickly becoming a must have for any business or organization that depends on a website or application (so just about every business with its doors still open).
Just to give you an idea, In this post were going to cover:
There are three things guaranteed in this life: death, taxes, and downtime. The heavyweights in the tech industry lose millions of dollars each and every minute they’re systems are down. They invest large sums of money annually in preventative measures, and yet, these applications still go down occasionally.
Any number of things can cause downtime such as; errors in code, hosting provider issues, some form of human error (most common), equipment failure, natural disasters, and malicious attacks.
The bottom line is; despite preventative measures and the reason for application downtime, its going to happen at some point or another.
Aside from the physical cost, web browsers are notoriously impatient and unforgiving. All it takes is a few instances of downtime, without a status page or some form of downtime communication, and you may lose the loyalty of that user forever.
Aside from leaving your website or application when its down, they likely take their business or attention directly to your competitor. So what can be done to prevent these costs and reputation damage?
How many times a day would you say you check your applications availability? Ten, maybe eleven? No matter how many times you check, it never feels like quite enough.
Uptime tools check availability up to one hundred times a day. It doesn’t matter how diligent you and your IT team are, checking your application one hundred times isn’t a reasonable thing to do.
When the application does experience downtime, you, and your users will immediately receive direct messages called incident updates. These incident updates…
How frustrating is it when you start up your favorite mobile app or check up on your favorite website, and it isn’t working properly?
While their isn’t much that can be done about the downtime itself, status pages and incident updates allow you to get the word out quickly and easily. Uptime.ly uptime tools have built in functionality that can turn a status page into a mini forum that integrates with Disqus so that end users can communicate directly with your team in an orderly fashion.
© Copyright StatusCast 2022 | Terms & Conditions | Privacy Policy