A recent survey from AppDynamics and Dimensional Research found that:
1) 88% of respondents indicated putting a monetary value on the cost of poor user experience was important, but only 38% quantified that themselves despite having the analytical tools to manage user experience
2) 74% of respondents blamed a lack of data integration for the disconnects between teams and gaps in monitoring end-to-end app performance
3) Nearly 70% of respondents didn’t benchmark their performance data against competitors
We know from numerous reports on the subject that outright downtime typically costs organizations hundreds of thousands of dollars per hour, or well over $5,000 per minute. We don’t yet have clear cost estimates for poor performance however. Admittedly, this is hard to quantify, as on/off is simple to measure, whereas performance problems would need to be measured on a spectrum (along with the corresponding estimated costs).
Most customers (and providers) have come to expect “five nines” of uptime, that is 99.999% uptime. This usually does not include scheduled maintenance, but sometimes will. There are some software providers claiming 100% uptime but when giants like Google go down, “five nines” seems significantly more credible a claim.
Rather than continue to compete on uptime as the absence of downtime, providers are now being forced to compete on uptime as the absence of slowness (Aberdeen Group recently re-iterated the sentiment “slow is the new downtime.”)
It is not merely uptime, not merely optimal speed, but consistent speed (the ‘uptime’ of speed) that end-users now care about. And just as you owed it to your end-users to inform them of instances of downtime (no software company wants their customers knowing their app is down before they do), so do you owe it to your end-users to inform them when there’s a disruption in the peak performance of your application.
While it may be uncomfortable to admit that there’s a problem (especially if it’s not the first one in recent memory), it’s better that you be transparent about it, for two reasons.
First, you establish trust with your end-users. They know that they don’t need to watch out for you trying to hide things from them and take advantage of their ignorance- you’ll come to them before they need to come to you when a problem arises.
Second, you establish appropriate expectations for your app’s performance. Yes, it is unfortunate that you had to send out two alerts this week that the software is having issues, but better that and your end-users know what to expect than to not say anything and have your end-users wonder why your software is so buggy and inconsistent.
This hits on both aspects of credibility in customer experience – you want your customers to trust your product, trust your words, and trust that their business relationship with you will help them succeed, because you’re both on the same team.
It’s been argued that the chief advantages of a SaaS offering—from the customer perspective—include expedited time to value, reduced hosting and licensing costs, out-of-the-box or easy to add-on integrations, and ongoing upgrades.
Anyone with actual experience buying and using SaaS though will tell you that the value you realize initially may be offset further down the line by frustratingly persistent bugs up to and including short-term but wide-scale software outages. Integrations and upgrades, even if they work as intended themselves, can cause disruptions with other important features. Reduced hosting and licensing costs will hold true, but even with the protection of an SLA it can be hard to enforce SaaS application uptime (i.e. “is the software accessible or is the application down?”).
The woes of these customers may be answered with a “well, you can always choose a different vendor” but the fact of the matter is they don’t really want to choose a different vendor. They don’t want to go through the hassle of research and implementation and training that’s associated with changing vendors. It’s inefficient and unpleasant. They just want their current, generally decent SaaS provider’s application to have more consistent performance.
And it’s actually not that hard to demonstrate that to your end users. In fact, a large piece of the problem is communication-related rather than technical.
As a SaaS provider, it is possible to minimize the issues your customers experience and to highlight for them how well your application expedites time to value, integrates with other relevant products, and offers ongoing upgrades.
In an SD Times article earlier this year, Erwan Paccard at Dynatrace proposed five things you can focus on to best achieve this:
But all of this is back-end stuff – how do you demonstrate this reliability and due diligence to your end users? And what if, despite your best efforts, the application experiences downtime anyway?
When a SaaS product goes down, customers immediately begin bombarding Support, possibly the executive team as well, if they are a VIP customer. It isn’t long before IT/DevOps starts getting questions from all sides about what went wrong, why it went wrong, how long it will take to fix, what can be done to avoid it in the future, etc. All while they are still trying to identify and repair the issue in the first place!
By communicating SaaS application uptime, you achieve two goals:
By communicating your uptime status regularly, you are also establishing a pattern of normalcy so that when there is an incident, it is easy for the customer to place it in the context of a long record of honestly-reported reliability.
Transparency builds trust which yields cooperation – so you and your customers can enjoy a business partnership rather than the kind of adversarial relationship that is unfortunately characteristic of some vendors and their customers.
By pre-writing messages that can be triggered by alerts from your APM system, either immediately, with a delay, or pending manual confirmation, you allow your IT/DevOps team to automate downtime communication to the precise degree they’d like to. This allows them to maintain focus on what they do best – troubleshooting to discover and repair application performance issues.
The availability and response time of your website is critical to cultivating a positive customer experience, especially in the ecommerce world. Site24x7 has a long history of helping customers identify ways to optimize the availability and response time of their customers’ respective websites, through end-to-end monitoring and monthly reporting. With these tools, you can quickly identify what’s wrong and where’s there’s room for improvement.
While Site24x7 has always undertaken efforts like this to make monitoring easy, now it makes communication with end-users easy as well.
A recently-forged partnership between hosted status page provider StatusCast and Site24x7 allows customers who integrate these two products to notify their own site visitors/end users when Site24x7 detects performance issues, and when uptime is fully restored. Users can subscribe to receive these uptime status updates via their preferred communication channel, for instance email, text/SMS, Slack, twitter, etc.
Best practice suggests writing general communications to customers based on the types of issues you encounter most frequently. By keeping the language non-technical, you are actually doing a better job of helping the end-user understand the impact on them.
When the alert is fired in Site24x7 it will automatically trigger an update in StatusCast, populated with the info you’ve pre-written. You can configure StatusCast to either send the message out immediately, to wait a set period of time before sending the message out, or to populate the update but not send anything out without manual confirmation.
Whether it’s scheduled maintenance or an unplanned disruption, StatusCast supports your organization’s efforts to be transparent, accountable, and professional in your communications with your own customers.
It’s all about SaaS–even in your home.(or subscription-based offerings, if not software).
From jumpstarting growth to reducing churn to growth milestones, all built from experience, readily-accessible SaaS tips make it even easier for would-be innovators to keep themselves on the right trajectory.
As one SaaS writer from Andreessen Horowitz put it, the key is customer success and ROI:
“Mass SaaS is merely a logical step in a world where our subscription and delivery behaviors are all facilitated by the smartphone. But integrating SaaS into a consumer business isn’t a magic bullet; businesses will face challenges as they still need to constantly improve products, operations, and overall offerings. Customer acquisition is important of course, but as all good enterprise SaaS founders know, customer success becomes the top priority because it’s significantly easier to retain a customer than to acquire a new one. Likewise, customers still need to feel they’re getting a positive return on their investment. Otherwise, they’ll churn. Period.”
SaaS application uptime is obviously a critical element of customer success and perceived ROI—if they can’t use your application, that’s a major problem (but not without mitigation, see Status Pages section below). Application performance management (APM) is the best tool to prevent application downtime.
While it used to be that APM was a cumbersome process that happened after the fact and itself actually negatively impacted application performance due to the system resources it required, APM has since gotten sophisticated and lightweight enough to be almost predictive and can run concurrently with code being deployed without a major impact on application performance.
But even with modern APM technology, there are regularly reports about how much money SaaS companies lose each year due to application downtime, much of it due to reputation damage with their customers.
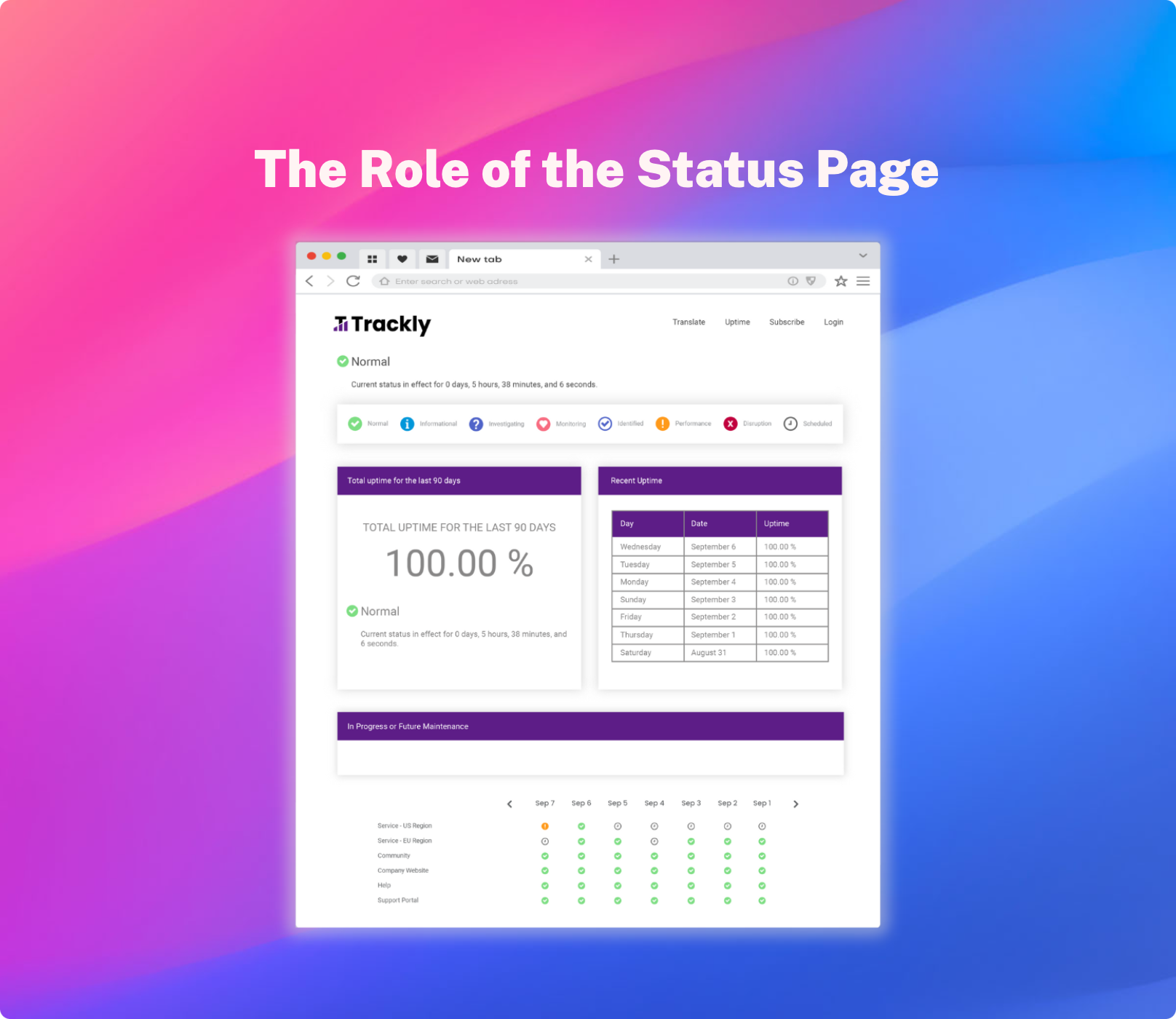
Application status pages are an affordable way to address this reputation problem.
While the real-time information your IT or DevOps teams gets from your APM is useful to them, it can also go a long way towards demonstrating ROI to customers.
By using a status page to keep your customers in the loop about when your software is down (for scheduled maintenance or due to unexpected issues) and when it’s back up again, you’re demonstrating transparency and accountability.
By sharing your historical SaaS application uptime (both when there is recent/imminent downtime and when there is not), you’re reminding your customers that disruptions are rare.
This does not change the fact that there was a disruption, but it does help recontextualize it in the bigger picture of the customer’s growing relationship with you as a trusted provider.
Status page response time is the amount of time that passes between when an incident occurs that impacts application availability or performance and when your status page communicates that an incident has occurred to your end users. We’ll get into a more nuanced understanding of how this does work and should work further below. For now, it’s enough to say that this and its correlation to customer satisfaction is the metric you pay attention to to improve your response to downtime-related churn risks.
The number and quality of testimonials (or reviews or other forms of social proof) are also extremely valuable as SaaS customer experience marketing data. This not only tells you how happy your customers are but how ready they are to evangelize your product to their peers, friends, etc. This is the metric you pay attention to to improve your response to success. This can be valuable for non-SaaS companies as well, but SaaS companies in particular ignore it at their own peril.
Time to value (TTV) is arguably the most important SaaS metric—as its name suggests, it’s the metric you use to track how long it takes for a customer to understand the value of your product. Understanding what your TTV is will be instrumental to several aspects of SaaS sales and marketing. For instance, it’s vital to know your TTV in setting up free trials, as the duration of your trial should take into account your average TTV.
By optimizing the way you communicate inconvenient truths (like application downtime) to your customers, you establish trust and can mitigate much of the damage the disruption has done to your brand reputation.
Earlier this month, Pete Mastin of Cedexis shared an interesting perspective about uptime and application performance at Data Center Knowledge. In short, he noted that there are simply too many points of failure for any software to realistically achieve 100% uptime without a multi-location, globally load-balancing system. This proposed solution potentially allows for 100% uptime (when following best practices), and may or may not be economically feasible.
Regardless of whether or not 100% uptime is achievable (theoretically or practically), customer expectation demands a hosted status page to communicate application availability changes.
When it comes to uptime and application availability, customer expectations usually fall on the “perfect execution” end of the spectrum. To put it in a more familiar context, customer expectations about functionality and usability are similarly high. In both instances, the failure to deliver on expectations results in customer dissatisfaction.
As anyone who has worked in software can tell you, a diverse mix of factors could contribute to a customer feeling like your product fell short of “perfect execution” in terms of functionality and usability. Examples might include disconnects between Sales and Product teams prior to customer acquisition, between trainers and customers during onboarding, and between support and customers once the customer has “gone live” (a more or less official milestone depending on the complexity of your application).
Similarly, as Pete Mastin notes, a number of factors can compromise the “perfect execution” of application availability (i.e. 100% uptime):
“Whether it is the UPS system, the cooling system, the connectivity or any of a myriad of subsystems that keep the modern data center working, N+1 (or its derivatives) does not guarantee 100 percent uptime… Connectivity issues (both availability and latency) are out of your control, from acts of god to acts of man. Peering relationships change, backhoes continue to cut fiber and ships at sea continue to drag their anchors. Hurricanes, earthquakes, tornadoes, tsunamis and rodents on high wires will continue to avoid cooperation with data center needs.”
You expect your customer support and/or account management teams to communicate with each customer professionally when addressing that customer’s issues with the functionality and usability of your solution. More importantly, your customers expect your staff to address them in such a timely and respectful manner. This is true whether their issue is caused by a newly discovered bug or simply user error. The onus is on your company either way.
Similarly, your customers expect communication from your company about disruptions to application availability. Whether it is unexpected downtime or scheduled maintenance, the onus is on you to communicate with your customers in a timely, professional manner.
In instances of both functionality and availability, any number of factors can contribute to customer dissatisfaction (disrupted expectations) – and timely communication is an essential component to properly resolving that dissatisfaction.
A hosted status page provides end users with an historical record of uptime for your application (this can be a helpful tool in de-escalating a volatile conversation with an angry customer). Hosted status pages will usually also provide a way for customers to subscribe to alerts for more timely communication about instances of downtime.
This process can be automated (through integration with your Application Performance Management system), password-protected (and/or restricted by IP address), and personalized by details such as geography or component – so only the end users impacted will receive the relevant alert.
Exceptional customer service is not a substitute for an intuitive user interface, but it is still a major differentiator for many customers having usability issues. Similarly, a hosted status page is not a substitute for 100% uptime (if such a thing is even possible and/or feasible), but it represents a significant benefit to customers having issues accessing your solution. StatusCast makes it easy to provide this benefit by helping you set up a hosted status page in a matter of minutes.
Click here for more information about how you can better communicate uptime and downtime to your customers.
Internal staff and end users need to be informed about changes in uptime, and an application status page can help tailor that communication to each audience.
Last month, APM Digest’s #1 prediction for this year was “2015 is all about user experience.” But user experience itself is all about uptime and about communicating that uptime in a way that is accessible, timely and convenient to the end user, via an application status page. Anand Akela, Sr. Director and Head of APM Product Marketing at CA Technologies, noted in that first APM Digest prediction:
“In 2015, Application Performance Management solutions will not be just about the performance of applications or business transactions, but its focus will now move to helping enterprises inspire their users and deliver exceptional user experience in order to earn their loyalty.”
Similarly, later in the predictions, Denis Goodwin, Director of Product Management at AlertSite by SmartBear, noted under #9 “APM dashboards serve diverse stakeholders”:
“These platforms will also necessarily evolve to become more “answer-centric”- with the ability to surface up differing levels of actionable insights and pertinent detail to a diverse group of stakeholders – business owners, IT/Ops personnel, QA engineers and developers.”
Denis’ point is a good one, but it is one step shy of its logical conclusion. Not only do APM dashboards need to serve Executive staff, as well as IT, QA and Dev teams, but they also need to serve end users.
An application status page simplifies this for you. By taking a few minutes upfront, it allows you to:
An application status page reduces the cost of downtime (which can be as much as $240,000 or more in reputation damage alone) by improving the communications side of user experience, preventing the downtime fire from spreading into a PR fire as well.
By making things clear for your end users and easy for your own teams, you best position your organization to automate much of the communications side of user experience and to focus on what actually requires your full attention: solving performance issues quickly and completely.
Every decent business resource, whether it is a book, school or magazine teaches the importance of customer service. The problem we have in heeding that advice is that customers have to be receptive, available and listening. In the SaaS world, one thing we get is that our customers login each and every day. Minimally we can agree that when they use the service, they do indeed login.
When a customer logs in you have a great opportunity to communicate with them. One place in particular to convey information should be within your application status page. This page should provide application monitoring information that is specifically suited for end-user consumption. Many SaaS companies think of their application status page, as the trust center. Organizations even have their URL as trust.domainname.com. Why is it that we don’t then take advantage of this, by providing more application monitoring related information to build trust?
Within StatusCast, a platform for providing end-users with real-time application status, the capability exists to report on informational items. You want to make your status page sticky? Then give your customers information that is easily consumable and worthwhile. This type of end-user information is significantly different from the kind of information that would be communicated via an application monitoring solution that focuses on communicating with internal IT staff.
One of those bits of information we like to provide on our end-user application status page is change log information. In case you are more of a marketing focused vs. technical person, a change log is the record of changes that happen between versions of your software. Sometimes change logs might show the actual computer programming functions, but in this case we are primarily discussing change functionality that would be relevant to the user of the system.
Change logs have various formats that they follow, but this isn’t the importance here – the relevant fact is that a customer can go to one place to find out complete status about the application that they depend on. Additionally because StatusCast unifies communication, allowing the SaaS vendor to send out messages to several destinations through one interface – your customer/end-user can receive application status alerts through twitter, SMS and social avenues.
Developing a customer-focused application monitoring page that includes the elements mentioned above will set you apart from the competition and will help you to establish a more trusting, lasting relationship with your clients. Remember, your customers are becoming smarter every day, and many of them need to be reminded why they are with your service vs. a competitor. You have a weapon in your arsenal plain as day; use your trust center to effectively communicate with your customer, and retain that customer for life.
There probably isn’t one person reading this right now that hasn’t encountered a similar situation where they have gone through very difficult times with a loved one. I know I have been bedside many times with various family members over the years, wishing we did more things, enjoyed life to its fullest and in particular, communicated things that really mattered before it was too late.
Frequently I read business to business blogs and they are infiltrated with statistics and study after study trying to make their point. Such as Gartner, who claims the average large corporation has an average of 87 hours of system downtime per year. OK, I had to sneak something like that in, but really, in the end – none of these stats matters much. We can probably all agree that we will all have system uptime, and system downtime-and we’ll continue to have it. What matters is the relationship you have with your customer, in advance and during the difficult stretches, to help minimize the cost of downtime.
I normally try to avoid reading articles like this – they sell fear and warn of impending doom. I mean who wants to be reminded of life’s “down times”. It’s half the reason I avoid Facebook. They could call it complainbook, deathbook, etc. Unfortunately, difficult times are reality, and from it we must take away lessons (if we are smart enough to pay attention), that teach us we need to communicate better and share more not less. A lesson we can apply to customer service; communicate and share more, not less.
Instinctually we know that if we try to bullshit our way through a situation and don’t come out clean from the start, that one lie turns in to five lies, and so on. It’s this very fear of communicating something bad that prevents us from communicating. For every communication that should occur (but doesn’t), we cause an exponential problem that we could have desisted from if only we communicated it in advance.
Don’t waste your time building your own application status pages and app status communication platform. Use a provider that specializes in doing just that with little to no work involved. Yes! I’m pumping a company, I am a co-founder of www.statuscast.com. Better communication with your customers leads to better IT customer service and cuts down on the cost of system downtime. Your customers will love you for it and the ones that don’t; well, you can’t please all the people all the time.
© Copyright StatusCast 2022 | Terms & Conditions | Privacy Policy