


While technological advancements continue to shape our digital landscape, even the most advanced systems, databases, and applications can experience significant downtime. When tech giants like Google and Amazon are not immune, businesses must prepare for such inevitable occurrences. Here we'll dive into the startling implications and severe costs associated with system downtime.
Average Application Downtime Per Year
Remaining competitive in today's landscape requires heavy reliance on digital infrastructure, and as a result, even the biggest and most sophisticated organizations are susceptible to a small failure in any one critical system cascading into a prolonged outage. A Gartner study reported an alarming 87 hours of system downtime annually for corporations. Meanwhile, Dunn & Bradstreet found that Fortune 500 companies endure an average of 1.6 hours of system downtime weekly, amounting to 83.2 hours annually. These figures underscore a fundamental truth: system downtime is inescapable. The focus should pivot to:
- Establishing the cost of downtime
- Adopting an Incident Management Strategy for swift recovery
- Anticipating uptime threats for quicker root cause analysis and identification
- Instituting preventive measures and a status page for real-time updates for employees or customers
Identify Threats to System Uptime
Timely identification of potential threats is key to minimizing downtime cost and enhancing MTTR (Mean Time To Repair). Preparing for these threats ensures a more rapid and effective response. Common threats include:
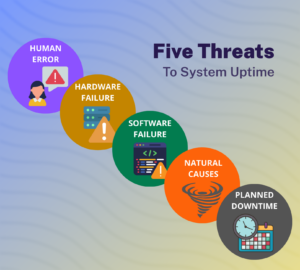
Human Error: Responsible for 50% to 75% of datacenter downtime, common mishaps range from accidentally unplugging equipment to inadvertent emergency shutdowns.
Hardware Failure: While predicting hardware failure is tricky, most incidents occur at the beginning or end of a machine's lifecycle. Regular maintenance can reduce such threats.
Software Defect/Failure: Even though less common, software failures can be as damaging as viruses and malware targeting servers and databases.
Natural Causes: Catastrophic events like floods, fires, and storms can wreak havoc on systems and their underlying infrastructure.
Planned Administrative Downtime: Though not a “threat” per se, these scheduled downtimes still result in lost employee productivity and financial implications.
The Domino Effect of Downtime
System outages don’t occur in isolation. Their repercussions cascade through various facets of an organization. Imagine a large multinational corporation with diversified operations spanning across multiple continents, and tens of thousands of employees across various departments. Their headquarters manages a vast network of branches, manufacturing units, research facilities, and sales offices worldwide.
One morning, the company's primary communication system experiences an unexpected outage due to a server malfunction. The initial impact is immediate: employees can't access their emails, virtual meetings are postponed, and inter-departmental communications are stalled. But as the minutes turn into hours, the second and third-order effects of the outage start becoming evident.
Decision-making Delays: Key decisions that rely on inter-departmental collaboration are postponed. An ongoing merger negotiation with another firm, which needed critical data from the finance team in another continent, is now in limbo because the required documents are inaccessible.
Operational Backlogs: The manufacturing unit, awaiting instructions from the central team, finds itself in a standstill. With no clarity on the production schedule due to the communication gap, the assembly line stops, leading to potential productivity loss in thousands of hours.
Research and Development Interruptions: The R&D team, many time zones removed from headquarters, relies heavily on real-time data from their test facilities in a third country. With the system down, they can't access this crucial data, pushing back their project timelines.
Sales and Customer Relations: Sales representatives, preparing for client pitches, can't pull the latest data or presentation materials. Scheduled client meetings get postponed, potentially risking significant contracts.
Employee Morale and Productivity: As the hours pass by, employee frustration mounts. Tasks get delayed, leading to longer work hours and reduced morale. The IT team, under tremendous pressure to restore services, faces a daunting MTTR (Mean Time To Repair) challenge.
Financial Implications: With every passing hour, the compounded downtime cost escalates. Beyond the immediate financial ramifications, the outage can delay quarterly financial closings, affecting stock prices and investor relations.
The cascade of second and third order effects of downtime underscores the severity of outages to critical systems that disrupt the fundamental operational capacity of large enterprises. What starts as a seemingly simple IT issue mushrooms into a corporate crisis affecting every stratum of the organization. During such incidents, a centralized status page monitoring mission critical systems, segmented into clusters of systems that are relevant to specific teams and departments, triggering status notifications to employees affected by the outage, become an invaluable tool for large organizations by mitigating the knock-on effects of downtime and protecting organization integrity in times of uncertainty.
Cost of Downtime Industry Wide
Quantifying the downtime cost can be a daunting task due to the many variables involved. An Information Week study with CA Technologies reported an astonishing $26.5 billion in lost revenue due to downtime across 200 companies surveyed. A study from Emerson Network Power further revealed an average downtime cost of $7,900 per minute, with typical downtimes lasting 90 minutes. This puts the average cost of a single downtime event at over $700,000. For large enterprises the cost is even higher, with the average downtime cost running between $1,000,000 and $5,000,000 per hour.
Real World Examples

- The 2017 AWS Outage: A simple human error led to a 4-hour outage for Amazon's S3 services. This not only affected Amazon but also countless websites and apps relying on S3. The estimated downtime cost was around $150 million for Amazon and upwards of $1 billion for all affected businesses.
- 2017 British Airways Global IT System Failure: In May 2017, British Airways faced a global IT system failure, leading to severe disruptions in their flight operations. Thousands of flights were canceled over a busy holiday weekend. Passengers were stranded all over the world, and the airline's communication systems were also affected, leaving passengers in the dark about their travel status. The outage was attributed to power supply issues, and it cost British Airways more than £100m.
Calculating the Cost of System Downtime
The repercussions of IT outages are felt immediately and ripple into the long-term, manifesting as tangible and intangible costs:
Tangible: Beyond the evident financial implications, the tangible costs of downtime often include:
- The time IT teams spend crafting incident notifications and managing tickets, detracting from solving the incident.
- Employee productivity, as they're left in the dark with disrupted workflows and unknown system status, keeping them from their normal tasks.
- Management teams' involvement in devising action plans and mitigation strategies.
- Potential client resource or data losses.
Intangible Loss: Intangible costs might not be immediately quantifiable, but their impact on a business can be long-lasting and, in some cases, irreversible:
- Damage to the brand's reputation.
- Potential business diverted to competitors.
- Strained customer relationships.
- Diminished employee morale and trust.
While the immediate tangible costs can be quantifiable, the intangible costs—like reputational damage and lost business—can have lasting repercussions on annual revenue.
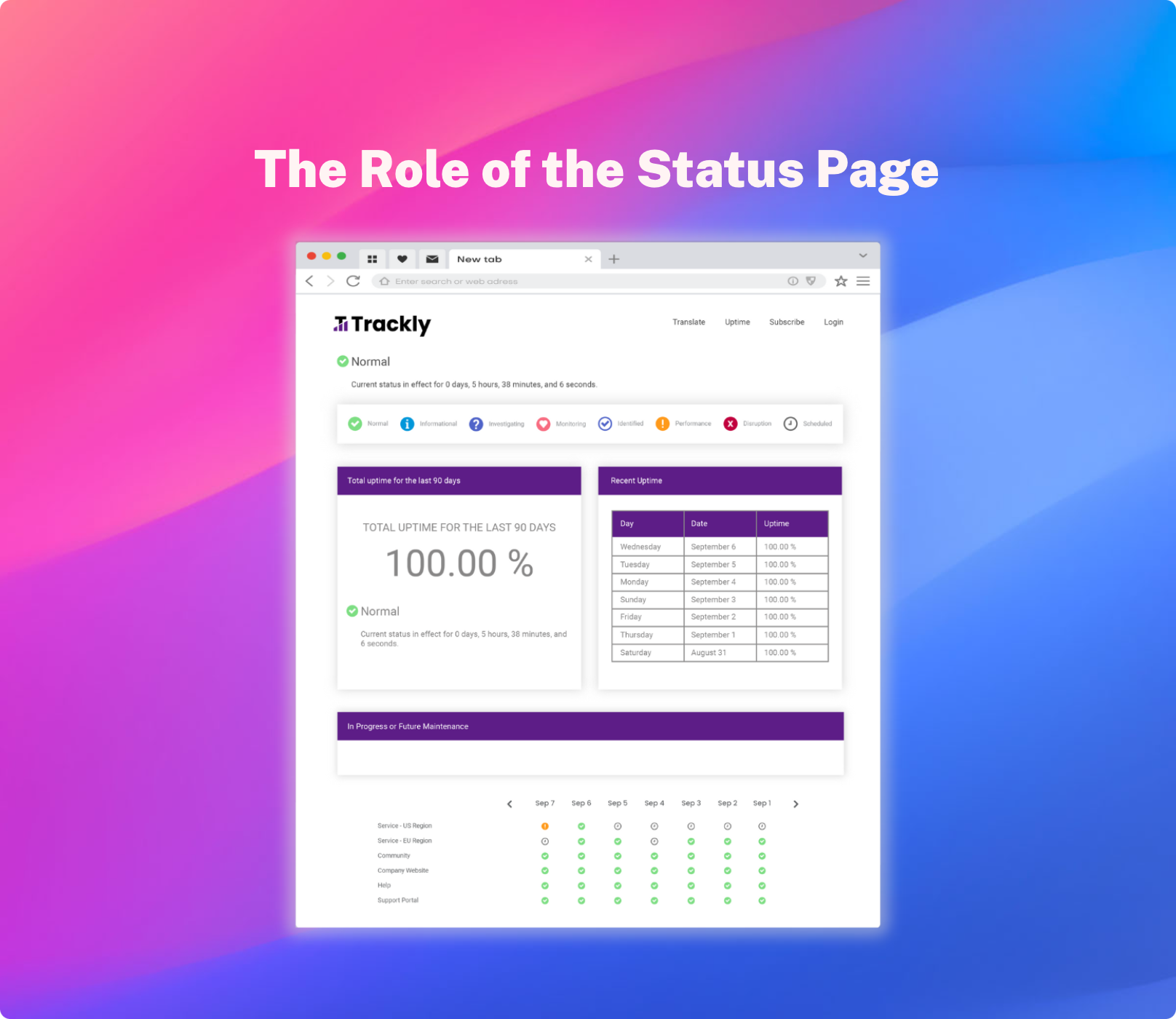
Keep End Users in the Loop with a Status Page
Amidst the chaos of a system outage, the status page emerges as a beacon of clarity, a single-source-of-truth for employees and end users to rely on. Status pages streamline incident communication, offering a real-time dashboard of the situation, distributing incident notifications, showing affected systems and third party services, monitoring uptime and SLAs. For IT teams, this means reduced distractions, enabling them to focus on incident resolution. For employees 0r customers, it means timely, coherent status updates, drastically reducing uncertainty.
For Your IT Team: Juggling system repair with constant updates can be overwhelming. A status page consolidates all critical information, freeing IT professionals to concentrate on resolving issues rather than fielding repetitive queries.
For Your Employees and Customers: A status page acts as a centralized hub for all outage-related information. Instead of being bombarded with technical data, users have a single-source-of-truth for all critical systems, and receive succinct, clear updates about components and services that are specifically relevant to them via their preferred notification channels.
Final Words on the Cost of Downtime
In an ever-evolving digital landscape, the cost of downtime isn't merely financial; it extends to trust, reputation, and long-term business relationships. Every minute counts, and the integration of a reliable status page is crucial in managing these disruptions. By being proactive, understanding potential threats, and communicating effectively, organizations can reduce downtime costs and fortify trust with their employees and customers, making them resilient in the face of inevitable IT challenges.