To understand the impact that stovepipes have on incident response, one need look no further than the 9/11 terrorist attacks that occurred in the United States. The CIA, DoD, and FBI all knew about the Al Qaeda terror threats before the planes hit the World Trade Center, but the 9/11 Commission found that a lack of data and intelligence sharing among the agencies limited each agency’s understanding of the looming terrorist threat; thereby, limiting their incident response. This lack of information sharing made it difficult for intelligence leaders to "connect the dots" and thwart the attack.
Thankfully, most IT stovepipe scenarios do not lead to such dire consequences; however, they do impact incident response when your IT systems go down. Wikipedia defines IT stovepipes as "systems procured and developed to solve a specific problem, characterized by a limited focus and functionality, and containing data that cannot be easily shared with other systems."
These singularly focused, non-integrated systems make the lives of IT help desk support personnel more time-consuming, more expensive and more frustrating (for both the support team and business stakeholders outside of the IT organization).
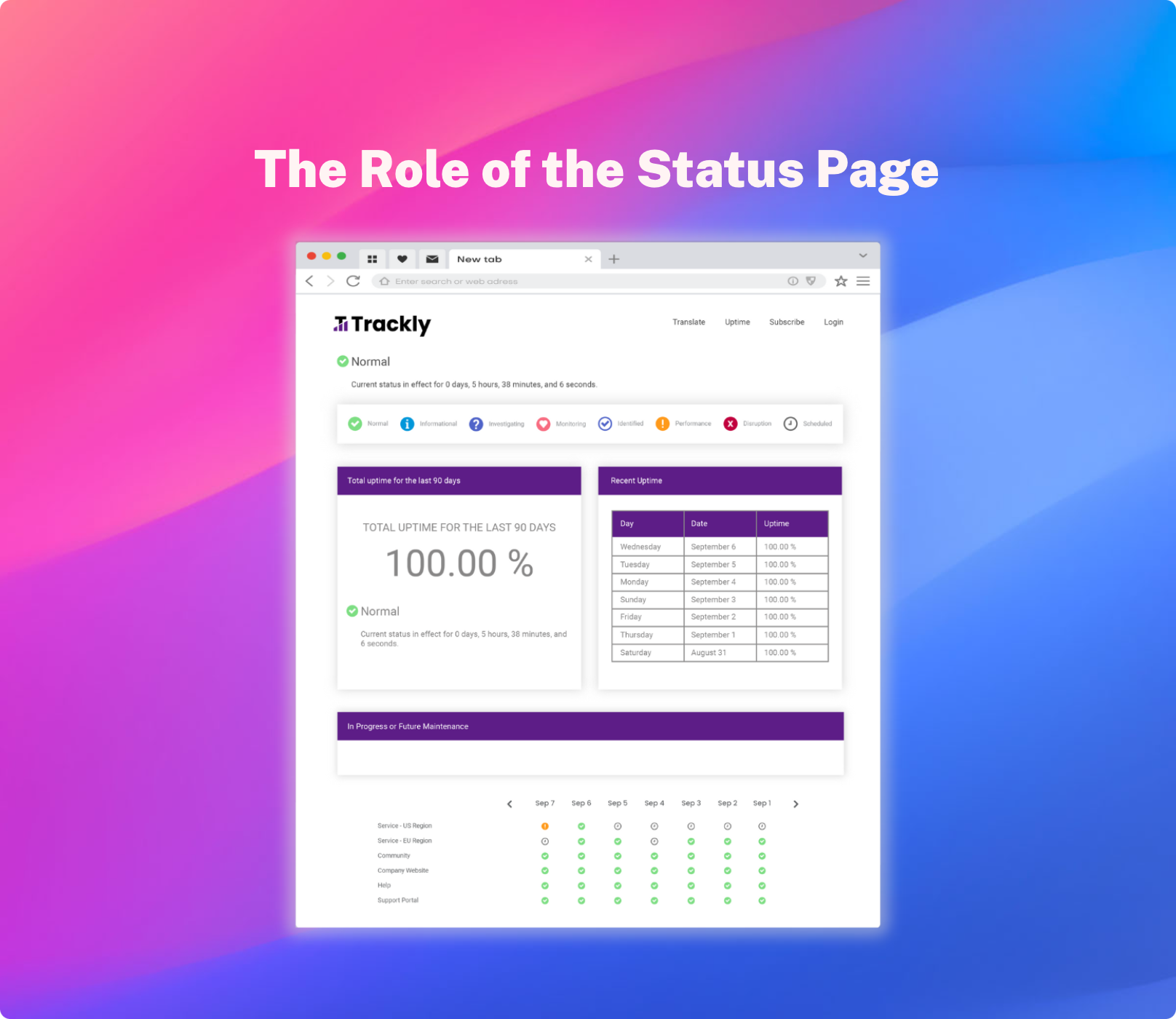
Employees and customers increasingly demand more transparency from corporate IT support teams, making stovepiped systems an "ugly" word with IT leaders. One of the best ways to meet the demand for more transparency is to invest in a Corporate Status Page.
A corporate Status Page provides a unified portal from which your IT help desk staff can assess all problems and planned outages across your IT ecosystem. Having a unified view provides your IT help desk team with holistic insight into the status of your enterprise IT systems & software. This all-encompassing perspective is invaluable when communicating with employees and customers about outages and planned maintenance.
By providing proactive incident management and planned maintenance communications, a corporate Status Page helps boost stakeholder trust, which in-turn leads to better customer and employee satisfaction.
In addition, by having all IT notifications feed into a single Status Page, you boost your IT help desk team’s productivity and reduce your IT support costs.
When looking to bust your incident response silos, you must ensure the Status Page solution you select meets the following requirements:
Allows for end-user-friendly, customizable pages and messages to provide stakeholders information they can use and understand versus "tech-speak"
If your business is plagued by silos in your IT incident management approach, you should consider a corporate Status Page. You’ll not only boost IT help desk team productivity, but also you’ll improve IT transparency, which has been proven to improve both employee and customer satisfaction.
If 2020 taught us anything, it is that a corporate Status Page is an IT ‘must have.’ With this one solution, IT leaders are able to address new challenges of remote work teams, as well as traditional issues — like high IT support costs, employee productivity, stakeholder transparency and IT team efficiency.
2020 was a year marked by the ‘virtualization’ of nearly every aspect of life. From doctor’s appointments to happy hours, we quickly moved live events to online environments like Zoom and Google Hangouts. Never was this truer than for corporate teams who were used to working in office buildings.
As professional teams transitioned to virtual work, companies faced a plethora of new challenges. Not only did they have to setup virtual work environments with the right tools for the job; but also, they had to determine how to keep their employees engaged, communicate with teams effectively and ensure a high level of employee productivity with remote work.
These new remote work challenges, along with traditional issues that weigh heavy on IT leaders’ minds — are improved with a corporate Status Page solution.
Reason #1
Reduced IT Help Desk Support Costs
If you have ever worked in a corporate environment, you surely have experienced the following scenario: You log into your laptop to start your day and find that Office 365 is not working. You, along with hundreds of your co-workers, call your IT help desk to report the problem and suddenly your IT support team is overloaded with too many support requests for the same issue.
IT support tickets cost on average $104. When you add this expense to the opportunity cost of employees and IT teams being less productive, you can see how much IT support tickets impact the bottom line of the business. By implementing a corporate Status Page, organizations can reduce inbound help desk costs by preventing the rise in incidents from happening in the first place.
IT leaders are able to save themselves the headache and cost that a surge in help desk requests creates by using proactive communication as one of the outage communication best practices and planned maintenance to employees as well as customers.
Reason #2
Higher Employee Productivity
Employee productivity is always a concern — whether your teams are in-office or working remotely. According to the 2015 HIS Markit study, North American companies lose up to $700 billion a year related to IT outages. This includes a 78% loss in employee productivity.
The total revenue loss from employees’ inability to access core systems during outages marks only the start of the negative domino effect. If the impacted employees also play customer-facing roles, the outage can impact customer service, sales, customer support and other customer-oriented business functions.
To protect against outages and resolve them quickly, many corporations have turned to corporate Status Pages to provide proactive and integrated incident management communications. By integrating all IT notifications into one interface and being proactive in sharing information with both internal and external stakeholders, IT teams are freed up from the flood of calls and emails they receive without a corporate Status Page. This ‘free’ time can be applied to resolving the problem at hand versus recording yet another ticket for the same issue.
Another way a corporate status boosts employee productivity is in the area of communicating planned maintenance information. By knowing in advance when maintenance will be performed, employees can better plan their workday, focusing on off-line tasks during the time when systems are unavailable. This ability to adjust their workday according to system availability means teams are using their time more wisely and are thus being more productive.
Reason #3
Greater IT Transparency
According to business.com, companies that embrace transparency as a core business value find that it leads to consumer trust, loyalty and business success. And why not? Transparency fosters trust, and trust is important for the health of every relationship – both personal and professional.
According to the Label Insight Transparency ROI Study, at least two-thirds of consumers would spend more if it meant buying from a transparent company and 94 percent rank transparency as the greatest factor in brand loyalty. In addition, Harvard Business Review notes that obtaining a new customer is anywhere from five to 25x more expensive than retaining an existing one.
Company transparency is also of utmost importance to employees. In fact, Forbes notes that employees indicate that transparency is the number-one factor in determining employee workplace happiness.
A corporate Status Page goes a long way toward providing IT transparency to both internal and external stakeholders. By providing proactive incident management and planned maintenance communications, a corporate Status Page helps boost stakeholder trust, which in-turn leads to better customer and employee satisfaction.
Reason #4
Improved IT Team Efficiency
By implementing a corporate Status Page, you not only free up your IT team to focus on higher value tasks, but, assuming your Status Page supports unified communication, you are also making your IT team more efficient in performing their tasks. Instead of spending considerable time using multiple notification interfaces across myriad IT apps and systems, with a corporate Status Page, IT teams use a dashboard that integrates all incident management notifications into one customizable dashboard.
Modern status page providers are able to fully integrate with all your external third party SaaS products. They can ingest their status in real-time and proactively forward new incidents to your IT team or directly to your employees. Imagine the time saved by a system that automatically notifies your employees of the next Office365 or AWS outage.
Reason # 5
Remote Work Benefits
SocialChorus and Pulse recently “surveyed 100 global enterprise IT leaders to uncover how they are prioritizing employee engagement and communications improvements…and the top technology features that would help them derive greater ROI from their digital employee experience investments.” 93% of IT leaders who participated in the survey said that employee engagement and communication is a higher priority initiative in 2020 as a result of the rise in remote work. In addition, 49% of these leaders agree they would “be able to better calculate ROI…and boost productivity with a unified view of analytics across all tools and platforms.”
A corporate Status Page addresses these IT leaders’ needs with one unified view of all incident management notifications. IT teams as well as other employees can be more efficient and productive, IT leaders are better able to perform ROI analyses and employee engagement and communication get a boost — all because of a corporate Status Page.
As 2020 draws to a close and we look toward a new year, IT leaders are advised to consider investing in a corporate Status Page. With this one solution, IT teams are able to do their best work while at the same time reducing IT support costs, boosting employee productivity, improving IT transparency and addressing the unique needs of remote workers.
Founded in 2013, StatusCast is a unified communications cloud-based platform that allows IT to easily communicate status and scheduled maintenance messages to its end-users with a powerful application status page. Want to see how a status page can benefit your business? Start your 14-day free trial or schedule a demo today!
Today’s news is filled with stories about the failures of IT and the impact to companies, consumers and brands. Because modern business relies heavily on IT, system outages and IT downtime have become a standard part of ‘doing business.’ 2019 saw several big outage stories. We’ve shared our Top 5 picks and discuss the importance of implementing an IT status page to help you successfully manage your organization’s IT downtime.
Because there are so many differences in how businesses operate, downtime can be cost between $140,000 and $540,000 per hour.
Salesforce’s outage in May of 2019 enabled Salesforce users inside companies to see all of their company’s data, with or without permission. This issue was compounded by the fact that Salesforce (in an effort to offer a quick fix) turned off permissions to its Marketing Cloud. This change caused sales agents and marketers around the world to lose access to their customer information. Salesforce took three days to fully restore access to the Marketing Cloud to all its 150,000+ customers. Without access to a CRM database marketer’s cannot send out emails, implement automated touch-points and capture/score new leads from company websites. No CRM also access means sales teams are left working manually from call lists and their recollection of proposals and sales contracts. In other words, sales and marketing teams that have standardized on the Salesforce platform came to a screeching halt during this system failure. The number of companies affected, the severity of the issue and the amount of time it took for the problem to be resolved, is what landed Salesforce on our Top 5 IT Outages of 2019 list.
According to Reuters, Slack now has 10 million daily active users on its platform. On June 28 of 2019, Slack users started noticing significant issues with performance that affected Slack’s most popular services–login, messaging, posting files, calls and other app integration. During the outage, Slack registered a 10-25% job failure rate. This error rate may not seem significant to some, but when you consider Slack’s 10 million daily user base, it is quite notable. For this reason, Slack makes our Top 5 IT Outages of 2019 list.
Google’s Gmail Meltdown
Most of us are familiar with Gmail because we have a free gmail email account. But, did you know that more than 5 million businesses have standardized on Google’s GSuite, which includes Gmail? Most of these businesses are smaller in nature, which makes the platform even more critical as smaller players have less of a buffer than their larger counterparts when it comes to closing sales, meeting customers’ needs and running operations.
In March of 2019 Google experienced a global outage that affected its Gmail and Google Drive services. For 4.5 hours Gmail users complained that they couldn’t send emails. Google Drive users reported that certain files would not open and that the Google Cloud was operating in a diminished capacity (very slow). Due to the widespread global impact and the number of hours the services were down, Google ranks in our Top 5 IT Outages of 2019.
Microsoft Office
Microsoft Office is prolific with 1.2 billion people (across 140 countries and 107 languages) using the platform. On January 24, 2019, the SaaS giant reported that customers in Europe couldn’t access their Office 365 Exchange online mailboxes. Every time a user tried to log into their email, the connection would time out, leaving them with no access.
Less than a week later, Microsoft again had an Office 365 problem that affected more services and a wider customer base. It turned out that one of Microsoft’s providers had introduced a software defect into its technology stack, which affected connectivity to Microsoft Office customers’ cloud resources. The sheer number of people affected by both of these incidents makes Microsoft Office one of our Top 5 IT Outages of 2019.
The common denominator among these Top 5 2019 IT Outages (with the exception of Snapchat) is the impact they had on business. It is conceivable that during these outages: Salesforce users in the sales and marketing departments of 150,000+ organizations couldn’t access their customer data, couldn’t run marketing campaigns and couldn’t capture sales leads effectively; Slack users couldn’t collaborate on new products and services which translated to a loss in development time; and employee productivity slowed and customer service suffered because files had to be shared via email versus Google Drive.
The other common thread among these companies is that they are all big industry players who have invested in communications tools to keep their stakeholders abreast of IT issues. But, what about the trickle down effect? What is the best method for their business customers to keep their stakeholders up-to-date. These businesses have to put in place communication channels to make their internal and external stakeholders aware of how outages affect their supply chain, operations, sales, marketing and customer service. According to Jonathan Hassell of CIO Magazine in “4 Ways CIOs Can Respond to a Service Outage,” communication is a critical ingredient to successfully mitigate an IT outage. In Jonathan’s words, “Communication can’t be an afterthought. It must be a high priority — second only to resolving the outage. Don’t make a bad situation worse by creating an information vacuum.”
Most companies focus on communicating externally to customers and the press regarding outages, but what about their other important stakeholders — their employees? Employees are the backbone of business as they support all client-facing functions like sales, marketing, service delivery, customer service and so on. When planning your IT downtime game plan, you should consider an IT Status Page to communicate with your employees and other internal stakeholders
Acorporate status page dramatically reduces your downtime costs by keeping employees informed and productive. The average cost of downtime for mid- to large-size companies is approximately $5,600 per minute.
By keeping internal resources up-to-date and providing them the information they need to do their jobs effectively, you ensure more stable and productive business operations while your IT team works to fix the underlying technology problem.
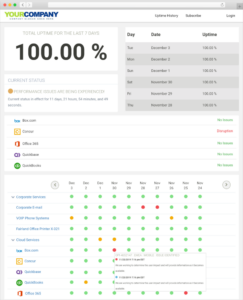
Sample IT Status Page
Learn More
https://www.crn.com/slide-shows/cloud/the-10-biggest-cloud-outages-of-2019-so-far-/2
https://data-economy.com/outages-downtime-system-failures-2019s-it-meltdowns/
Many reports have come out in the last 3-4 months evaluating the cost of application downtime, from the likes of Veeam, Infonetics and IDC. Late last year, the StatusCast blog shared data from the Ponemon Institute about the cost of application downtime, and included stats from Gartner for additional context. Here’s an update (and a breakdown) of who’s saying what about the costs of downtime and what it all means for your SaaS business:
Gartner (July 2014) – $336k/hr (with variance as high as $540k/hr)
Context: industry surveys
$5,600/min; $336k/hr (with variance as low as $140k and as high as $540k/hr)
Read more here.
IDC (Nov-Dec 2014) – $100k/hr or $500k+/hr for critical failure
Context: Fortune 1000 companies, with revenue $1.39BB+
Infrastructure failure: $100k/hr
Critical failure: $500k-$1MM/hr
Most common time reported to repair the failure was 1-12 hours (NB this is 1-3 hours if it’s restoring from a production failure)
Average annual cost of unplanned downtime: $1.25BB-$2.5BB
Read more here.
Veeam (Dec 2014) – $105k/hr or $130k/hr for critical failure
Context: 760 companies across several countries and industries, each of which employees at least 1,000 people; costs include missed sales opportunities, lost productivity and data loss
Mission-critical applications: $130k/hr
Non-mission-critical applications: $105k/hr
US companies suffer an average of 12 incidents of unplanned application downtime per year. These instances lasted an average of 1.6 hours for mission-critical applications and 3.3 hours for non-critical applications.
Max annual cost of downtime $11.2MM
Read more here.
Infonetics (Feb 2015) – up to $100MM/yr
Context: 205 medium and large business in North America affected by Information and Communications Technology (ICT) application downtime
Up to $100MM/yr
Read more here.
While application downtime can be reduced, it cannot be eliminated. You need to have a strategy in place to protect your reputation—and relatedly, your recurring revenue—when an incident occurs.
The best strategy is making it as convenient as possible for the end-user to learn about when a disruption occurs and to be updated as service is restored. This level of respect and consideration for the customer will immediately help in repairing the reputation damage incurred by the service disruption itself.
A hosted status page communicates the current status of your application, and includes an historical record of past performance and any notifications of upcoming scheduled downtime. StatusCast can extend the reach of this page by offering end-users the option of subscribing to updates via email, text message (SMS), twitter, etc rather than having to proactively navigate to the status page URL on their own.
StatusCast allows you to set up a hosted status page in less than 10 minutes that can easily integrate with your application performance monitoring (APM) tool (e.g. New Relic).
Integrating with your APM allows you to use StatusCast to translate the information you’re already getting from your APM into updates sent in terminology your end-users will understand and sent only to end-users affected by the particular disruption.
StatusCast also allows you to set whether those updates are sent automatically, with a set time delay, or will not send until receiving manual approval.
You can learn more about StatusCast here.
Recently, Aberdeen Group published a report titled Preventing Virtual Application Downtime – which was written by senior research analyst Jim Rapoza. The report claims that today 59% of applications – including those that are mission critical – are virtualized and Aberdeen believes that it is completely reasonable that in the near future this percentage will increase to 80% or more.
The report discusses the fact that application downtime is incredibly expensive – $686,250 is the average cost of an hour of downtime for large companies. For medium size companies the hourly cost is about $216,000 and for small companies it is about $8500. To attempt to avoid these costs, leading organizations implemented high-availability and fault-tolerant related systems and processes to prevent application downtime. Aberdeen suggests that “Best-in-Class” organizations pair high-availability software and fault-tolerant systems with processes that lead to a heightened ability to monitor and understand virtual applications and to detect and address potential issues.
Aberdeen found that 80% of all businesses are utilizing high-availability software and 56% were leveraging fault-tolerant servers. So, it appears that many businesses are employing best practices to attain high availability levels to keep their critical virtual applications running and to avoid the high costs of downtime.
Here’s the odd thing; according to Aberdeen’s research, the industry average for measuring performance of virtualized devices is only 46%. It’s the same percentage for measuring end-user satisfaction and only 20% measure ROI for implementing virtualization. So in the words of Jim Rapoza “if you don’t measure the performance of something, how can you ensure that it has high availability and no downtime?”
The thing is that although many organizations do things to prevent application downtime – they don’t do things optimally. Even those that are “Best-in-Class” organizations still can’t claim 100% uptime. Yes, you need to do your best to prevent downtime – but you will – at some point – go down.
I’m sure that you’re aware that application downtime costs a boatload of money. But let me start this blog by reinforcing something you already know. Aberdeen Group estimates that application downtime costs $110k per hour for an average company. Ponemon Institute claims application downtime costs $205k per hour and Gartner reports that it’s $42k per hour. Pick a number – they’re all big and significant. But this isn’t the whole story. The potential cost of application downtime is actually much, much greater. Let me explain.
The fact that so much money can be lost during application downtime results in a myriad of uptime monitoring solutions and application performance management tools. Companies like CA Technologies provide such solutions and there is no doubt that these solutions are of great value. However, even after you implement these tools you’re still going down. Machines break and humans make mistakes and there is nothing you can do about it. We live in an imperfect world. There is no magic pill that you can take that will ensure that you never have an outage.
As a case in point, look at Yahoo Mail. As recently as December 2013 they had an epic fail. A Twitter user @wonder_wendy, tweeted, “Very frustrated!!! My account has been down since Monday. Apparently due to “maintenance”, with no heads up. Terrible!” This my friends, sums up the hidden cost of application downtime. We all know about the costs reported by Gartner, Aberdeen and others. What we neglect to account for is the cost associated with brand damage. The costs associated with harming a reputation that we spent years and hundreds of thousands of dollars – if not millions – to craft. All can be lost in a single, poorly handled incident. And remember – these incidents are inevitable. You will go down.
Uptime monitoring solutions and application performance management tools are a form of preventive medicine. It’s like exercising. But when you get sick and you need some pharmaceutical grade medicines – that’s where something like Uptimely kicks in.
When the inevitable happens, and we have an application outage, it is crucial that we effectively communicate with our external customers to minimize damage to our brand and reputation. This isn’t the focus of uptime monitoring solutions and application performance management tools. These solutions are for alerting, and informing, internal IT staff. These tools are not meant to facilitate external communication with end-users. Yahoo did a very poor job of communicating with their end-users. This resulted to an uproar on Twitter, viral spread of negative word of mouth, and a major punch in the gut to Yahoo Mail’s reputation. The cost of such a poorly handled outage communication – priceless!
Yahoo is not unique in this regard. From our internal surveys, based on customers downloading our application status software, we know that less than 3 in 10 SaaS companies have a dedicated end user communication method outside of manually posting to twitter, sending out an e-mail, and posting on their website. Just researching this particular Yahoo Mail outage alone required me to jump between Twitter, Tumblr and Yahoo’s help page (their link is now dead) to try to figure out what happened. In fairness, there is a poorly placed status page but it doesn’t send SMS or e-mails (unless you go through Yahoo Mail, which was down – in other words don’t depend on your own systems to report downtime), it also doesn’t coordinate any customer discussion, overall uptime metrics or any type of historic service level reporting. Here is an example of how a status page should look.
It’s important to be proactive about communicating at the first sign of trouble. Often times IT or DevOps think they have the problem under control and they wait to convey issues, thinking it will be resolved quickly. Many well-known outages have a sudden spark and then the issue starts to spiral out of control, funneling its way through the system. Before you know it, you’re down for 24 hours, 1 day, 2 days, etc. If not handled properly from the start, suddenly what was an IT problem is now a PR nightmare. When you throw brand, loyalty, reputation and lost customers into the mix the potential losses are incalculable, and it could ultimately cost you your business.
While technological advancements continue to shape our digital landscape, even the most advanced systems, databases, and applications can experience significant downtime. When tech giants like Google and Amazon are not immune, businesses must prepare for such inevitable occurrences. Here we'll dive into the startling implications and severe costs associated with system downtime.
Remaining competitive in today's landscape requires heavy reliance on digital infrastructure, and as a result, even the biggest and most sophisticated organizations are susceptible to a small failure in any one critical system cascading into a prolonged outage. A Gartner study reported an alarming 87 hours of system downtime annually for corporations. Meanwhile, Dunn & Bradstreet found that Fortune 500 companies endure an average of 1.6 hours of system downtime weekly, amounting to 83.2 hours annually. These figures underscore a fundamental truth: system downtime is inescapable. The focus should pivot to:
Timely identification of potential threats is key to minimizing downtime cost and enhancing MTTR (Mean Time To Repair). Preparing for these threats ensures a more rapid and effective response. Common threats include:
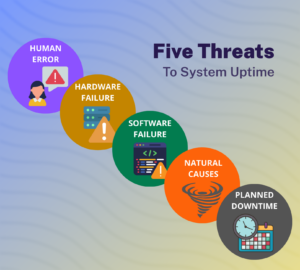
Human Error: Responsible for 50% to 75% of datacenter downtime, common mishaps range from accidentally unplugging equipment to inadvertent emergency shutdowns.
Hardware Failure: While predicting hardware failure is tricky, most incidents occur at the beginning or end of a machine's lifecycle. Regular maintenance can reduce such threats.
Software Defect/Failure: Even though less common, software failures can be as damaging as viruses and malware targeting servers and databases.
Natural Causes: Catastrophic events like floods, fires, and storms can wreak havoc on systems and their underlying infrastructure.
Planned Administrative Downtime: Though not a “threat” per se, these scheduled downtimes still result in lost employee productivity and financial implications.
System outages don’t occur in isolation. Their repercussions cascade through various facets of an organization. Imagine a large multinational corporation with diversified operations spanning across multiple continents, and tens of thousands of employees across various departments. Their headquarters manages a vast network of branches, manufacturing units, research facilities, and sales offices worldwide.
One morning, the company's primary communication system experiences an unexpected outage due to a server malfunction. The initial impact is immediate: employees can't access their emails, virtual meetings are postponed, and inter-departmental communications are stalled. But as the minutes turn into hours, the second and third-order effects of the outage start becoming evident.
Decision-making Delays: Key decisions that rely on inter-departmental collaboration are postponed. An ongoing merger negotiation with another firm, which needed critical data from the finance team in another continent, is now in limbo because the required documents are inaccessible.
Operational Backlogs: The manufacturing unit, awaiting instructions from the central team, finds itself in a standstill. With no clarity on the production schedule due to the communication gap, the assembly line stops, leading to potential productivity loss in thousands of hours.
Research and Development Interruptions: The R&D team, many time zones removed from headquarters, relies heavily on real-time data from their test facilities in a third country. With the system down, they can't access this crucial data, pushing back their project timelines.
Sales and Customer Relations: Sales representatives, preparing for client pitches, can't pull the latest data or presentation materials. Scheduled client meetings get postponed, potentially risking significant contracts.
Employee Morale and Productivity: As the hours pass by, employee frustration mounts. Tasks get delayed, leading to longer work hours and reduced morale. The IT team, under tremendous pressure to restore services, faces a daunting MTTR (Mean Time To Repair) challenge.
Financial Implications: With every passing hour, the compounded downtime cost escalates. Beyond the immediate financial ramifications, the outage can delay quarterly financial closings, affecting stock prices and investor relations.
The cascade of second and third order effects of downtime underscores the severity of outages to critical systems that disrupt the fundamental operational capacity of large enterprises. What starts as a seemingly simple IT issue mushrooms into a corporate crisis affecting every stratum of the organization. During such incidents, a centralized status page monitoring mission critical systems, segmented into clusters of systems that are relevant to specific teams and departments, triggering status notifications to employees affected by the outage, become an invaluable tool for large organizations by mitigating the knock-on effects of downtime and protecting organization integrity in times of uncertainty.
Quantifying the downtime cost can be a daunting task due to the many variables involved. An Information Week study with CA Technologies reported an astonishing $26.5 billion in lost revenue due to downtime across 200 companies surveyed. A study from Emerson Network Power further revealed an average downtime cost of $7,900 per minute, with typical downtimes lasting 90 minutes. This puts the average cost of a single downtime event at over $700,000. For large enterprises the cost is even higher, with the average downtime cost running between $1,000,000 and $5,000,000 per hour.

The repercussions of IT outages are felt immediately and ripple into the long-term, manifesting as tangible and intangible costs:
Tangible: Beyond the evident financial implications, the tangible costs of downtime often include:
Intangible Loss: Intangible costs might not be immediately quantifiable, but their impact on a business can be long-lasting and, in some cases, irreversible:
While the immediate tangible costs can be quantifiable, the intangible costs—like reputational damage and lost business—can have lasting repercussions on annual revenue.
Amidst the chaos of a system outage, the status page emerges as a beacon of clarity, a single-source-of-truth for employees and end users to rely on. Status pages streamline incident communication, offering a real-time dashboard of the situation, distributing incident notifications, showing affected systems and third party services, monitoring uptime and SLAs. For IT teams, this means reduced distractions, enabling them to focus on incident resolution. For employees 0r customers, it means timely, coherent status updates, drastically reducing uncertainty.
For Your IT Team: Juggling system repair with constant updates can be overwhelming. A status page consolidates all critical information, freeing IT professionals to concentrate on resolving issues rather than fielding repetitive queries.
For Your Employees and Customers: A status page acts as a centralized hub for all outage-related information. Instead of being bombarded with technical data, users have a single-source-of-truth for all critical systems, and receive succinct, clear updates about components and services that are specifically relevant to them via their preferred notification channels.
In an ever-evolving digital landscape, the cost of downtime isn't merely financial; it extends to trust, reputation, and long-term business relationships. Every minute counts, and the integration of a reliable status page is crucial in managing these disruptions. By being proactive, understanding potential threats, and communicating effectively, organizations can reduce downtime costs and fortify trust with their employees and customers, making them resilient in the face of inevitable IT challenges.
© Copyright StatusCast 2022 | Terms & Conditions | Privacy Policy