


Waste could take the form of mismanagement of resources (time, money, staff, tools, etc.) or of inconsistent or inefficient processes. John Rakowski at AppDynamics succinctly articulates this in the context of the APM world with his example: “multiple overlapping monitoring tools in a typical siloed enterprise mean physical waste (licenses etc), an inconsistency in the way they are used, and ultimately absurdity as alerts are not representative of the business.”
But there is an element to the waste issue he doesn’t consider, one that absolutely represents a mismanagement of resources and likely an inefficient process as well—when things go wrong, how is downtime communication handled?
Is it the DevOps team who is responsible for communicating the incident to customers – when the team’s attention is needed most on resolving the problem? How are the executive team, customer support team and other teams informed when there’s a disruption and when full functionality is restored?
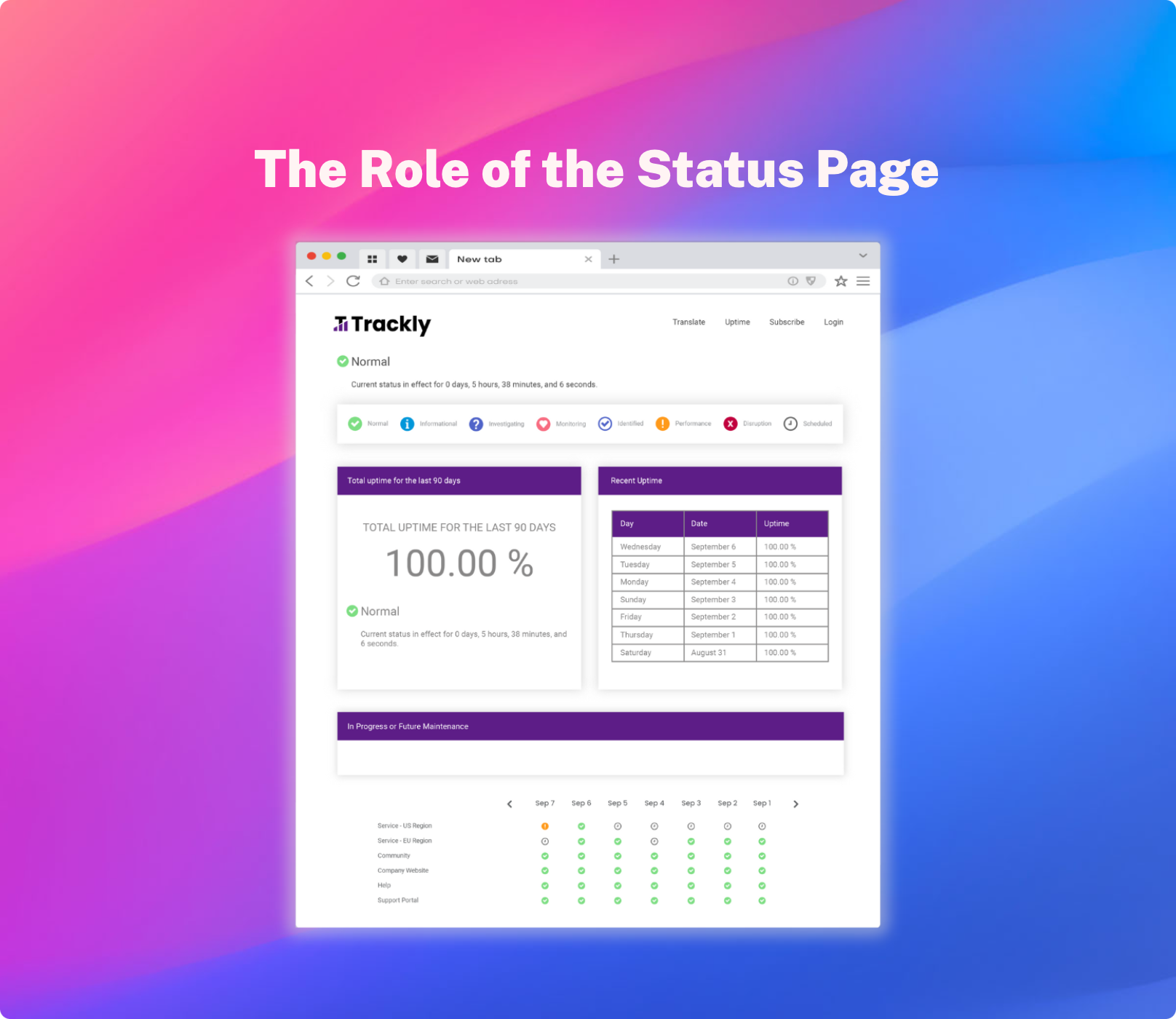
Using a Status Page to Efficiently Communicate Downtime
The language of these alerts can be crafted ahead of time, likely in collaboration with Marketing – to keep the message in terms non-tech-savvy users can understand.
The alerts sent by your status page can also be set to one of three protocols: automatic and instant, automatic but delayed, or pending manual confirmation – as not every bump in the road is cause for a customer communication. Similarly, alerts can be sent out that are tailored to specific components (maybe only east coast servers are experiencing issues, or maybe only users of a certain product are having trouble accessing the application). In this manner, you can ensure the right users are getting the right message at the right time, without placing any additional demands on your DevOps team.
By keeping your DevOps team focused on troubleshooting issues and anticipating and avoiding future problems, you are actually facilitating a second element of lean DevOps: continuous improvement. As Jez Humble, of Chef, noted in a presentation last month: “DevOps is not a goal, but a never-ending process of continual improvement.”
You can learn more about how a status page can help you become a lean DevOps organization here.