

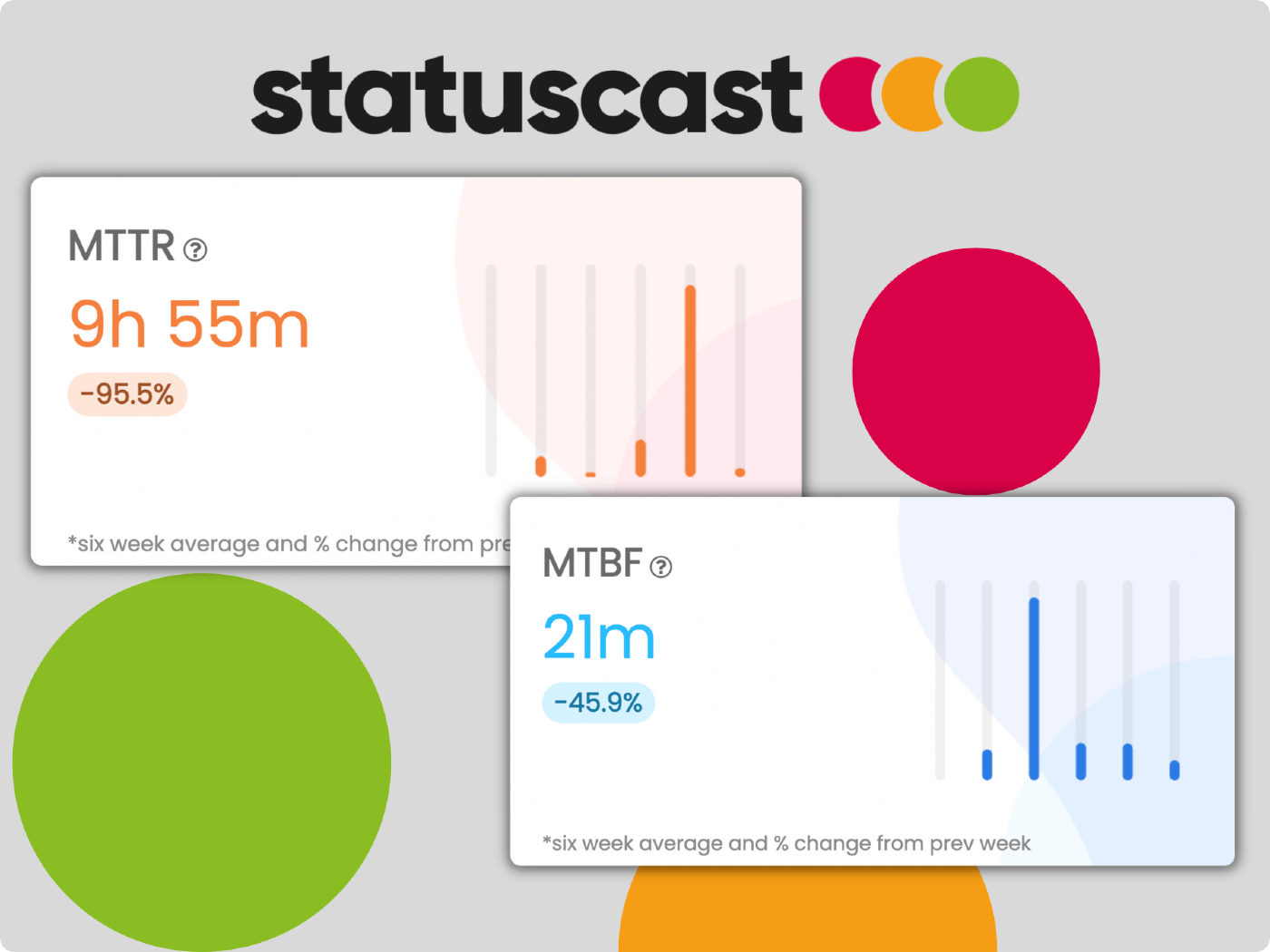
Mean Time To Repair, or MTTR, is a critical metric in IT incident management that measures the average time it takes to fix a system failure. The meaning of MTTR can be understood as the average duration needed for an IT team to recover from an incident. It is a fundamental metric for IT teams to track and analyze their efficiency in resolving incidents. MTTR is also an essential component of the bigger incident management lifecycle for IT departments, which includes identifying, prioritizing, diagnosing, fixing, and documenting incidents. In this blog post, we'll explore what MTTR is, why it's important, how to calculate MTTR, and what teams can do to reduce it.
MTTR, sometimes referred to as mean time to recovery or mean time to recover, is critical because it provides insights into the efficiency and effectiveness of an IT team's response to an incident. By tracking MTTR, IT teams can identify where bottlenecks occur and take corrective measures to improve the incident management process. A high MTTR may indicate failure points in the incident management process, such as delays in communication, inadequate resources, or poor documentation. On the other hand, a low MTTR indicates efficient incident response, which leads to increased system uptime and improved user experience.
Mean Time Between Failures
Measuring MTTR requires identifying the start and end points of an incident, such as the time an incident was reported and the time the incident was resolved. This metric is typically calculated by dividing the total time taken to resolve an incident by the number of incidents resolved during that period.
As we introduce new terms, we'll now have to explain what MTFB and MTTR mean, while sharing some tips on how to reduce MTTR and improve the overall reporting and resolving the ongoing IT issues.
It's important to note that MTTR is not the same as Mean Time Between Failure (MTBF) or Mean Time To Failure (MTTF), as MTBF and MTTF can be different, depending on the definition of MTBF being used, As we introduce new terms, we'll now have to explain what MTFB and MTTR mean, while sharing some tips on how to reduce MTTR and improve the overall reporting and resolving the ongoing IT issues.
While Mean Time Between Failures (MTBF) is often mentioned alongside MTTR, it is essential to note that this metric has two commonly used definitions. These definitions can lead to different interpretations of system reliability and dependability. We will explore these definitions and discuss the pros and cons of each.

The first definition of MTBF refers to the operational hours between the end of the last incident and the beginning of the next incident. This definition focuses on the actual uptime of a system or component, excluding the time it takes to repair or replace it. This approach offers a more optimistic view of system reliability and may be more suitable for measuring non-critical systems where downtime doesn't significantly impact business operations.
Pros:
- Provides a measure of actual system uptime, which can be helpful for assessing system availability.
- May be more relevant for non-critical systems where downtime has less impact on business operations.
Cons:
- Excludes the time it takes to repair or replace a component, which could lead to an overestimation of system reliability.
- May not be appropriate for critical systems where downtime has a significant impact on business operations.

The second definition of MTBF involves the total time between each failure, from the start of one incident to the start of the next. This approach provides an idea of how frequently incidents occur, including the time it takes to repair or replace a component. This definition is more conservative and can be a better fit for measuring critical systems where downtime has a significant impact on business operations.
Pros:
- Provides a more comprehensive measure of system reliability, including repair and replacement time.
- May be more appropriate for critical systems where downtime has a significant impact on business operations.
Cons:
- Can result in a more pessimistic view of system reliability, potentially leading to unnecessary investments in redundant systems or over-engineering.
- May not accurately reflect system uptime, as it includes repair and replacement time.
In conclusion, the choice of MTBF definition depends on the context in which it is applied and the specific objectives of the organization. For non-critical systems, using the first definition may be more relevant, while the second definition can be more appropriate for critical systems. Understanding the pros and cons of each definition can help organizations choose the most suitable metric for their needs, ensuring they accurately assess their system reliability and make informed decisions about maintenance, investment, and incident management.
Solving The MTTR Puzzle
On how to reduce MTTR, IT teams should take some measures, like investing in automation tools to speed up incident resolution. Also, they need to improve communication channels between teams while creating a well-documented incident management process and conduct regular training on the topic. It's also essential to prioritize incidents based on their impact on the business and allocate the necessary resources to resolve them efficiently.
Several solutions are available to help teams reduce MTTR in IT, such as incident management software, monitoring services and automation tooling. Incident management software provides a centralized platform to track and manage incidents, assign tasks, and communicate with teams. Reporting tools help identify incidents before they affect users and reduce the time it takes to diagnose and resolve them. Automation can help speed up incident resolution by automating routine tasks, such as restarting servers or running diagnostic tests.
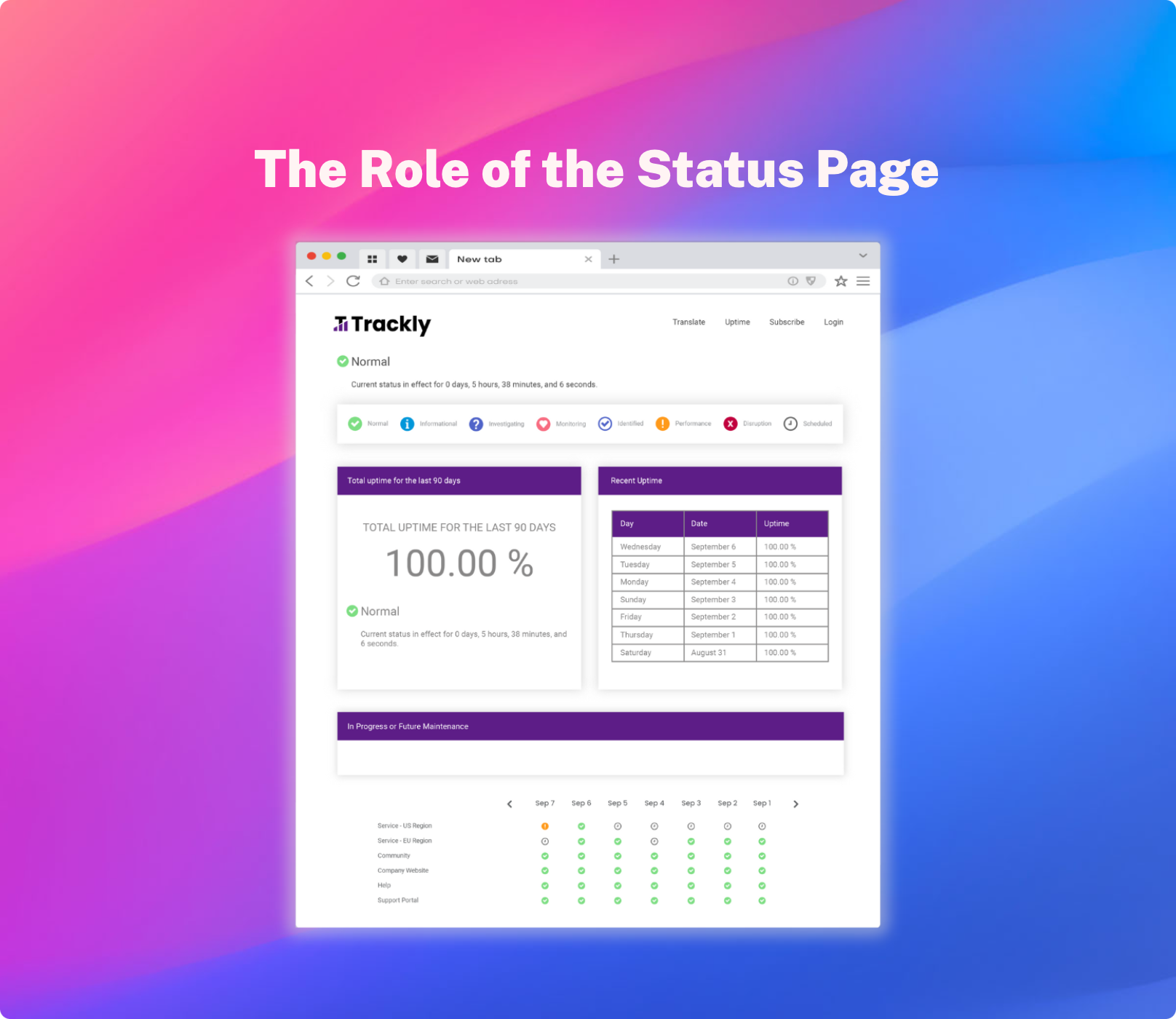
An internal private status page is also an effective tool that can help reduce MTTR by enabling employees to track the progress of an outage from start to finish. This page can provide real-time updates on the status of an incident, including the steps being taken to resolve it and the estimated time to resolution. This allows employees to stay informed about the incident, reducing the number of support calls and emails received by the IT team. Moreover, employees can get a sense of how long an incident may take to be resolved, which can help them plan their work around the outage. By providing transparency into the incident management process, an internal private status page can help increase employee confidence in the IT team's ability to resolve issues quickly and efficiently, which can ultimately lead to a faster MTTR.
In addition to providing transparency into the incident management process, an internal private status page can also help reduce the noise and distractions that IT teams face when trying to resolve an incident. By proactively communicating updates and progress on the incident through the status page, employees are less likely to contact the IT team with questions or concerns. This helps reduce the volume of support calls and emails, which can often be a significant distraction for IT teams during an incident. By freeing up the IT team's time and resources, they can focus on resolving the incident more efficiently, which can lead to a faster MTTR. An internal private status page not only provides a centralized platform for employees to track the progress of an incident, but it also helps reduce the noise and distractions that IT teams face during an outage, leading to a faster resolution time.
In conclusion, Mean Time To Resolution is a critical metric in IT incident management that measures the average time it takes to fix a system failure or issue. It provides insights into the efficiency and effectiveness of an IT team's response to an incident and is essential for improving incident management processes. To reduce MTTR, IT teams can take several measures, such as investing in automation tools, improving communication channels, and creating a well-documented incident management process. By tracking and reducing MTTR, IT teams can improve system uptime and user experience, which ultimately leads to a more productive and profitable business.