

In the realm of IT, disruptions and outages are not just inconveniences—they are critical events that can undermine the operations of businesses, impacting services, and user experiences. The landscape of IT incidents is vast, encompassing everything from minor glitches to significant outages that can halt operations and cascade into major business failures. Recognizing that there are various potential culprits for these disruptions, this blog will delve into the myriad causes of IT incidents.
The Usual Suspects of IT Incidents
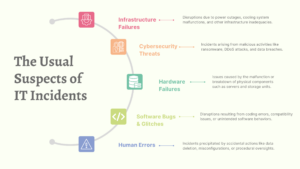
1. Infrastructure Failures:
Infrastructure failures stand as a primary catalyst for IT incidents, encompassing a wide spectrum from power outages to cooling system breakdowns. The backbone of IT operations, physical infrastructure, is susceptible to various unforeseen failures that can precipitate significant downtime. These failures often result from a complex interplay of outdated equipment, maintenance oversights, or environmental factors. The fallout can be dramatic, disrupting essential services and leading to operational paralysis. Recognizing the vulnerabilities inherent in the infrastructure your organization relies upon is pivotal in crafting proactive strategies to mitigate the severity and duration of such disruptions.
2. Cybersecurity Threats:
The digital domain is perpetually under siege from a range of cybersecurity threats, forcing organizations to constantly battle to protect their data and systems from malicious attacks. Cyber threats encompass a broad range of malicious activities, including ransomware, phishing, DDoS attacks, and more. These attacks exploit vulnerabilities within the system, seeking to compromise, steal, or ransom sensitive information. The impact of such threats extends beyond immediate data loss or service disruption; their impact on daily operations and service integrity can erode stakeholder trust and incur substantial financial and reputational damage.
3. Hardware Failures:
Hardware failures represent a tangible risk to IT services, where the malfunction of physical components like servers, storage units, or networking hardware can lead to substantial data loss and service interruptions. Unlike software issues that might be patched remotely, hardware failures often require physical interventions, making the recovery process more prolonged and complex. These failures might stem from natural wear and tear, manufacturing defects, or inadequate environmental controls.
4. Software Bugs and Glitches:
Software bugs and glitches represent a pervasive challenge in the IT landscape, where even minor programming errors can lead to catastrophic service disruptions to end user applications. These anomalies within software applications or operating systems can trigger a cascade of problems, ranging from minor user interface issues to critical security vulnerabilities or complete system crashes. The origins of these bugs are diverse, stemming from complex codebases, compatibility issues across different environments, or unintended interactions between various software components. Given the intricacy of modern software and the rapid pace of development, identifying and rectifying these bugs requires diligent testing, continuous monitoring, and timely updates.
5. Human Errors:
Human errors are an often-underestimated source of IT incidents, encompassing a range of mistakes from accidental data deletion to configuration errors. The complexity of IT systems, combined with the possibility of oversight or misunderstanding, can lead to significant unintended consequences. These errors highlight the importance of addressing the human element in IT operations, which involves fostering a culture of vigilance and continuous learning, aiming to minimize the risk of errors that could lead to widespread disruptions.
Mitigating IT Incidents with StatusCast
Enhanced Incident Communication
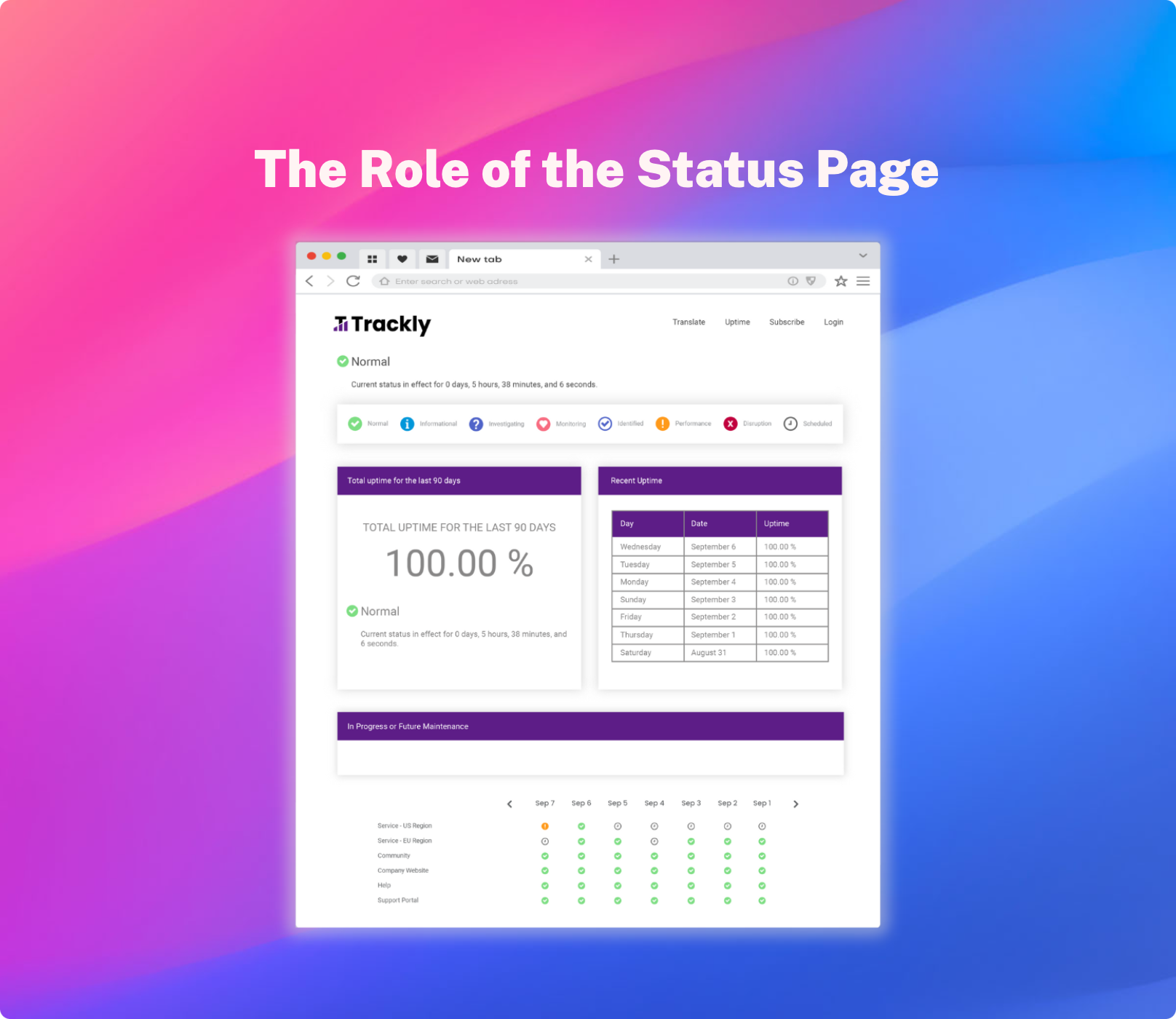
StatusCast redefines IT incident communication through its centralized status page, offering an integral platform for real-time updates on the status of critical components and services. By acting as a single-source-of-truth, it becomes an indispensable resource for employees or customers experiencing IT disruptions, ensuring they have immediate access to accurate and current information. This transparency is key to reducing frustration and building trust during downtime, as stakeholders are consistently informed about the state of IT services. Effective incident communication also helps to minimize lost employee productivity during outages; by keeping stakeholders informed, organizations empower their teams to activate contingency plans swiftly, maintaining business operations with minimal disruption. This strategic approach to communication not only enhances operational resilience but also reinforces stakeholder confidence in the organization's ability to manage IT incidents.
Proactive IT Notifications
The platform's capability to dispatch preemptive notifications about planned maintenance ensures users are well-prepared for potential disruptions. StatusCast also enables various strategies for highly personalized notifications, from component subscriptions to audience groups and custom status page views; which all make it possible for those affected by IT disruptions to be notified and kept in the loop before they encounter an outage themselves, preventing uncertainty and frustration among stakeholders.
Improved Incident Response
StatusCast offers out-of-the-box integrations with various APM and Observability platforms. It acts as a sophisticated conduit, funneling essential data from a variety of sources into a single pane of glass, drastically mitigating technical debt and complexity in the incident management process. This enables IT teams to effectively filter, prioritize, and respond to alerts without juggling multiple systems or succumbing to alert fatigue; by ensuring comprehensive visibility and seamless coordination across teams and tools, StatusCast minimizes IT downtime and bolsters operational resilience.
Post-Incident Analysis
StatusCast has built out automation and advanced functionality around Root Cause Analysis (RCA), enabling businesses to not just react to IT incidents, but to proactively prevent their recurrence. Recognizing the exhaustive cycle of addressing repetitive issues, StatusCast’s RCA functionality is designed to empower organizations to work smarter, not harder. It provides versatile RCA templates and unparalleled incident reporting capabilities, making it a unique offering in the incident management space. This focus on post incident analysis allows teams to identify and dissect the underlying causes of incidents—be it infrastructure misconfigurations, scalability issues, or external dependencies—thereby transforming temporary workarounds into long-term solutions. With StatusCast, organizations gain the ability to anticipate potential problems through early identification of recurring patterns, facilitating a shift from reactive measures to a proactive stance.
Conclusion
In navigating the complex landscape of IT incidents, understanding potential causes and implementing a proactive incident management strategy are paramount. StatusCast's new approach to incident management, and it's battled tested ITSM products, provides an unparalleled incident response stack that can help businesses mitigate the significant costs of IT outages. As organizations continue to adapt to the challenges of IT incidents, IT departments that embrace solutions like StatusCast will be ahead of the game in building a more resilient and robust IT infrastructure, safeguarding critical business operations and maintaining the trust of their stakeholders when systems go down.