


If you care about the uptime status of your website or SaaS application, there are two really great pieces of content shared last month that you should look into. One is an article on continuous testing from Parasoft Corporation, featured on DZone. The other is a recorded presentation on Application Performance Monitoring (APM) by Expected Behavior, from the Full Stack Toronto conference.
Continuous Testing with DevOps
The DZone article covers shifting from an automated testing mindset to continuous testing. It argues that this is essential for groups taking a DevOps approach to software deployment. It also advocates for changing the essential pre-deployment question from “are we done testing?” to “does this candidate for release have an acceptable level of business risk?”
It also presents some excellent questions, such as:
“Is there a clear workflow for prioritizing defects vs. business risks and addressing the most critical ones first? And for each defect that warrants fixing, is there a process for exposing all similar defects that might already have been introduced, as well as preventing this same problem from recurring in the future? This is where the difference between automated and continuous becomes evident.”
Maintaining a high SaaS application uptime will only increase in difficulty if you do not have such a process in place.
APM is the Next Unit Testing?
Expected Behavior’s Full Stack conference presentation draws parallels between unit testing and application monitoring to underscore why APM is worth the investment. Though APM systems may seem “too expensive” to those not already using them expertly, they will pay off for companies in the long run—just as unit testing was initially approached with trepidation but now has become standard.
As the complexity of software increases, the importance of detecting and documenting performance issues increases. That said, you don’t want to rigorously test everything – or you’ll get buried in data. It can be helpful to conceptualize what you need to monitor with an APM in the same way you’d conceptualize what you’d want to unit test. This approach can help you focus on measuring only what really matters to your software’s performance- such as interfaces between components.
The presenter from Expected Behavior, Nathan Acuff, offered this fantastic advice during the presentation as well:
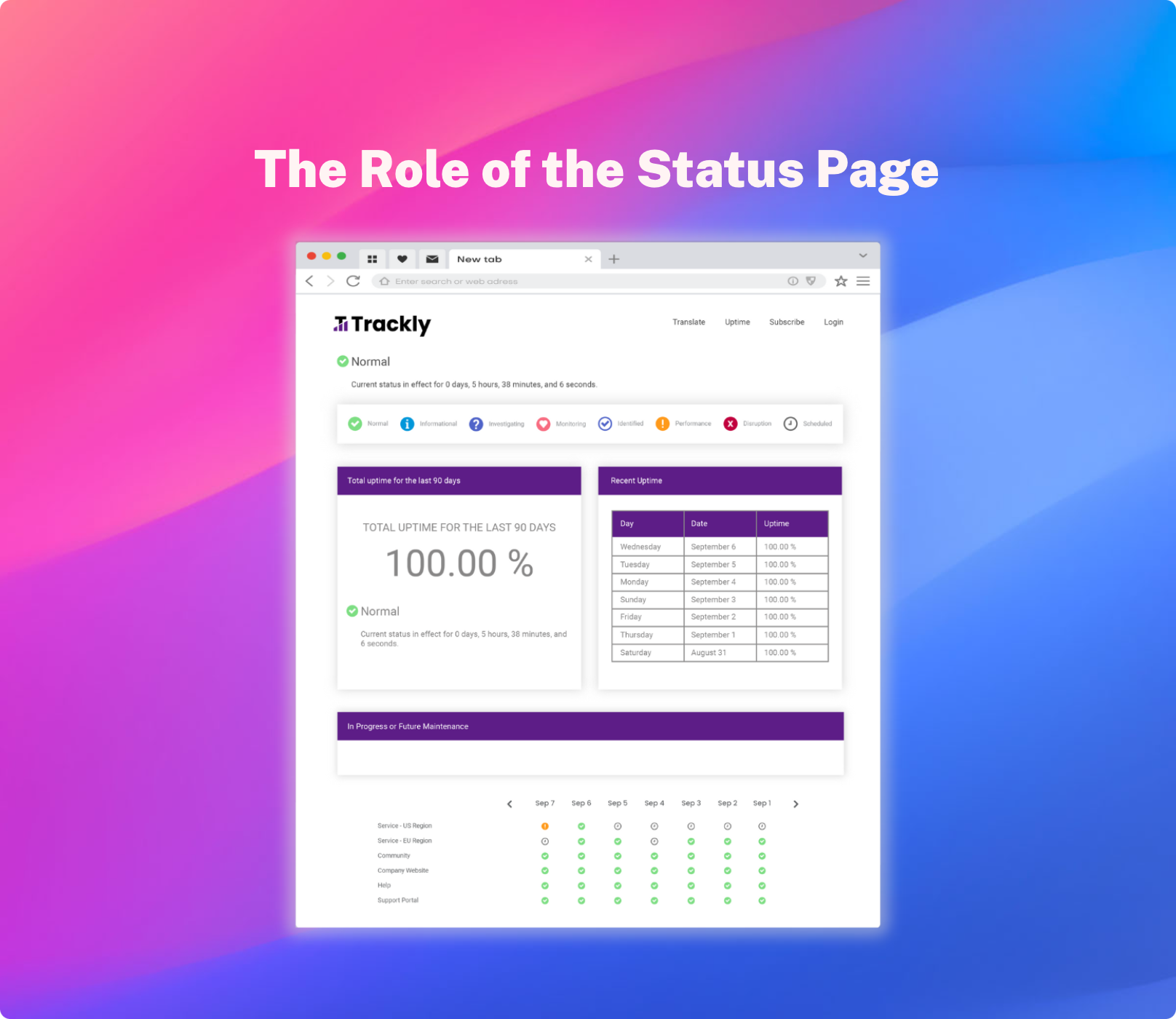
Measuring Partner Uptime Status with a Status Page
While your software’s uptime performance may be fine, there are often components that rely upon external partners or providers- and when these suffer slowness or outright downtime, your customers are still going to hold you accountable for the problem.
By offering regular updates to your end-users about the status of the various components that integrate with your solution or that your solution relies upon, you establish a baseline of trust in your product and in your organization’s management of the suite of tools that power your solution. It’s much easier for users to understand the context in which your product operates if you’ve proactively told them about it from the beginning, rather than only beginning to address it after they initiate the conversation with you unhappily.