


It’s been argued that the chief advantages of a SaaS offering—from the customer perspective—include expedited time to value, reduced hosting and licensing costs, out-of-the-box or easy to add-on integrations, and ongoing upgrades.
Anyone with actual experience buying and using SaaS though will tell you that the value you realize initially may be offset further down the line by frustratingly persistent bugs up to and including short-term but wide-scale software outages. Integrations and upgrades, even if they work as intended themselves, can cause disruptions with other important features. Reduced hosting and licensing costs will hold true, but even with the protection of an SLA it can be hard to enforce SaaS application uptime (i.e. “is the software accessible or is the application down?”).
The woes of these customers may be answered with a “well, you can always choose a different vendor” but the fact of the matter is they don’t really want to choose a different vendor. They don’t want to go through the hassle of research and implementation and training that’s associated with changing vendors. It’s inefficient and unpleasant. They just want their current, generally decent SaaS provider’s application to have more consistent performance.
And it’s actually not that hard to demonstrate that to your end users. In fact, a large piece of the problem is communication-related rather than technical.
Focusing on SaaS Application Uptime
As a SaaS provider, it is possible to minimize the issues your customers experience and to highlight for them how well your application expedites time to value, integrates with other relevant products, and offers ongoing upgrades.
In an SD Times article earlier this year, Erwan Paccard at Dynatrace proposed five things you can focus on to best achieve this:
- Application Performance Monitoring (APM) strategy – this is really just an umbrella under which the other four elements reside
- end user visibility – what is it like using your application on the user side? how are users actually using your application?
- bells and whistles vs. lean simplicity – it is better to have a fast, reliable core functionality than a parade of features that don’t always work as designed and/or contribute to sluggish performance
- mobile access – if your product isn’t easy to use on tablets and smartphones, you are missing a $370+ billion market
- load testing, availability monitoring, etc. – while #2 tells you what your users are doing, this one tells you what your users might do in the future. Stress testing before the holiday rush, for instance, is critical to your success when opportunity is actually knocking
But all of this is back-end stuff – how do you demonstrate this reliability and due diligence to your end users? And what if, despite your best efforts, the application experiences downtime anyway?
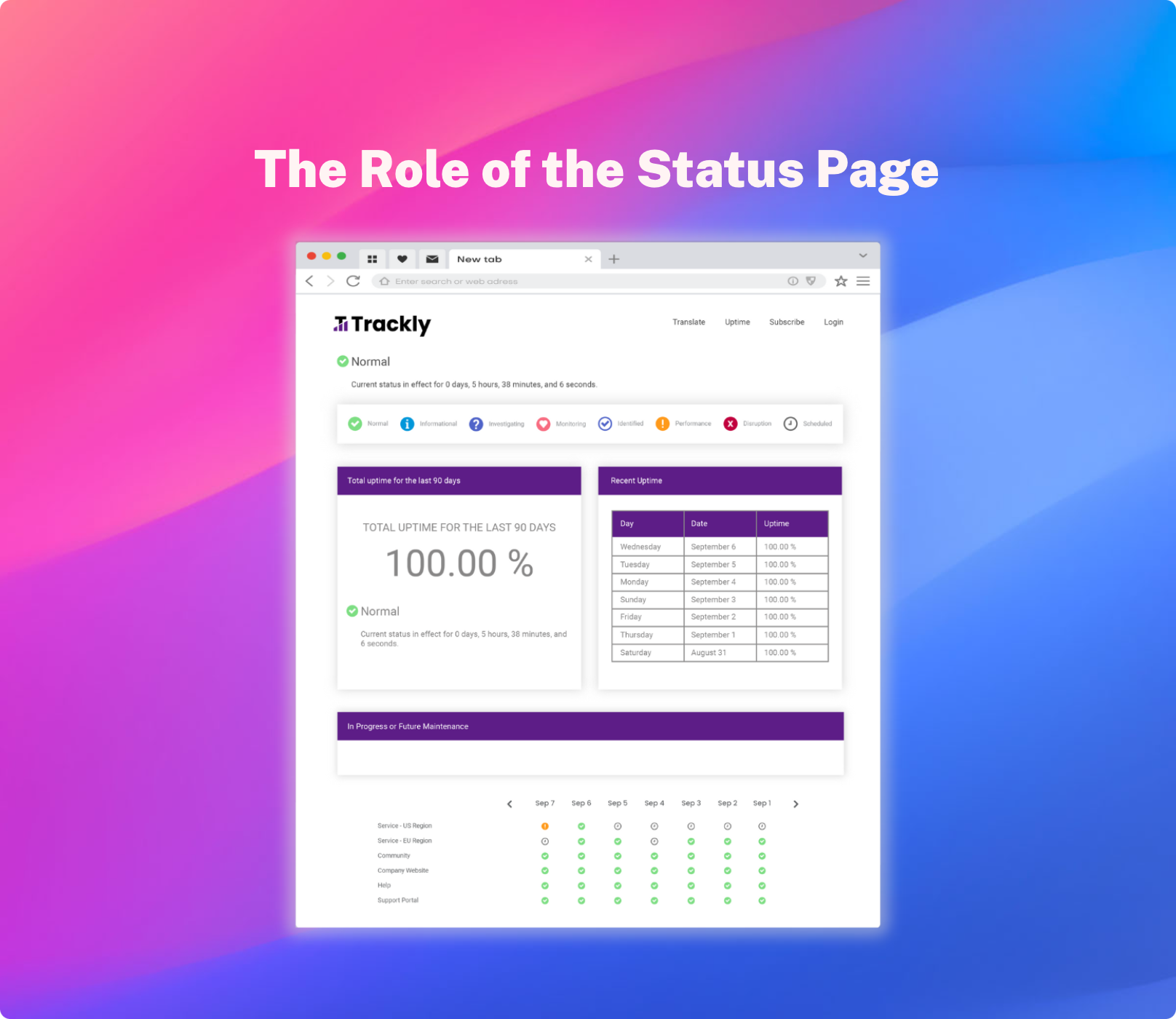
Communicating Uptime Status vs. Actual SaaS Application Uptime
When a SaaS product goes down, customers immediately begin bombarding Support, possibly the executive team as well, if they are a VIP customer. It isn’t long before IT/DevOps starts getting questions from all sides about what went wrong, why it went wrong, how long it will take to fix, what can be done to avoid it in the future, etc. All while they are still trying to identify and repair the issue in the first place!
By communicating SaaS application uptime, you achieve two goals:
- maintain a positive, transparent conversation with your customers about their trust in your product, and
- satisfy internal and external communication needs during a time of crisis, so that the team that will actually be doing the work to solve the problem can focus on doing so as quickly as possible.
Transparency and Trust
By communicating your uptime status regularly, you are also establishing a pattern of normalcy so that when there is an incident, it is easy for the customer to place it in the context of a long record of honestly-reported reliability.
Transparency builds trust which yields cooperation – so you and your customers can enjoy a business partnership rather than the kind of adversarial relationship that is unfortunately characteristic of some vendors and their customers.
Internal and External Communication
By pre-writing messages that can be triggered by alerts from your APM system, either immediately, with a delay, or pending manual confirmation, you allow your IT/DevOps team to automate downtime communication to the precise degree they’d like to. This allows them to maintain focus on what they do best – troubleshooting to discover and repair application performance issues.