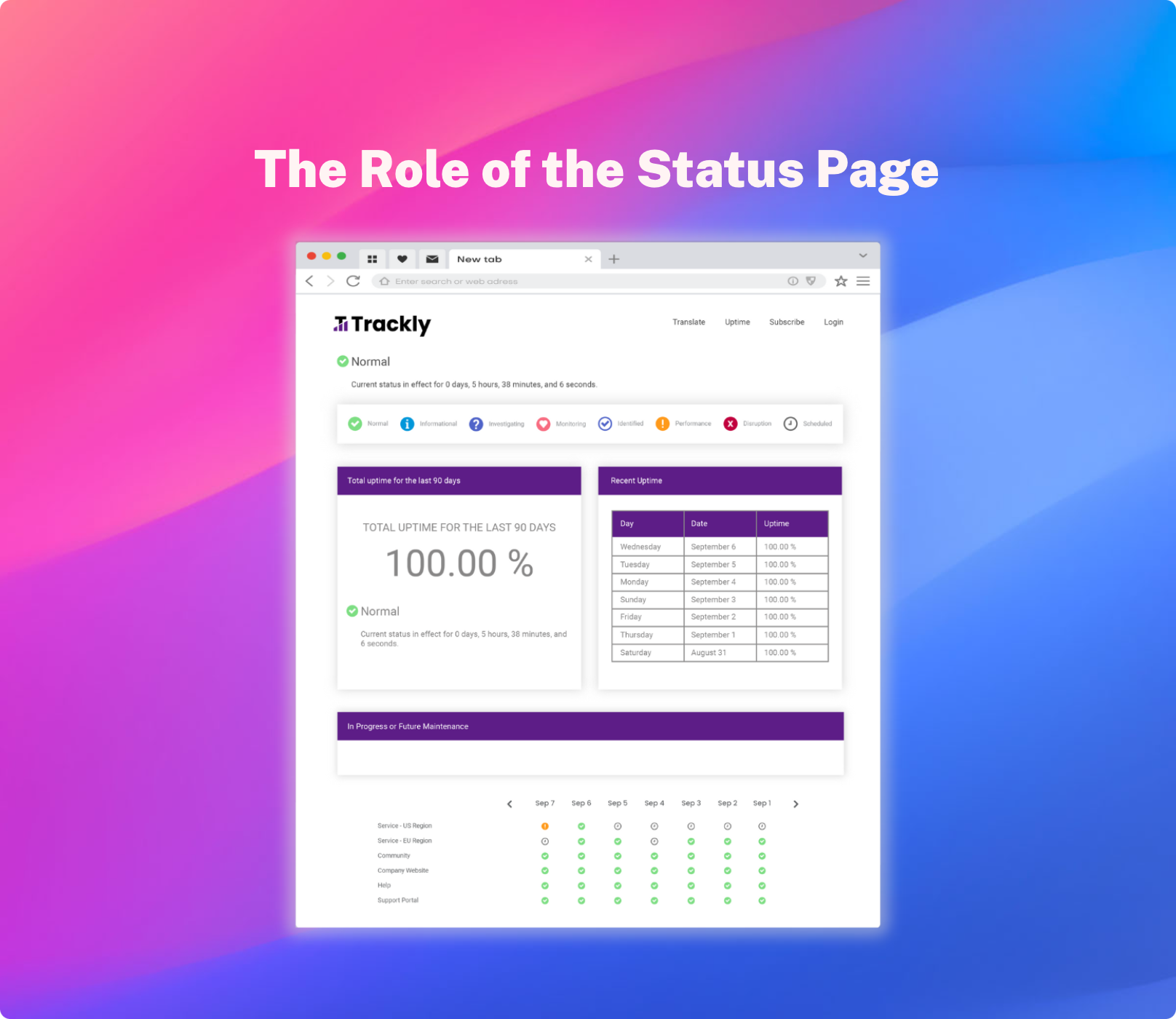


It’s simply a fact of life: cloud applications go down. Whether that application is running within your corporate firewall on your own private servers, or out in the “ethers”, how you react to downtime is critical. It doesn’t matter who your end-users are: employees, suppliers, or customers; communicating the status of unexpected and planned system events has a direct impact on your company’s top and bottom line.
Arrows in the Back
-
the product we sold was built and re-deployed thousands of times (long before slipstream deployments were commonplace and helped reduce downtime).
-
we had seemingly countless “scheduled maintenance” events where we had to upgrade either our hardware, software, or some other infrastructural component. You would be surprised how many times we had to announce scheduled maintenance because our co-location facility told us that they would be doing the same.
-
and as much as we hate to admit it, just like every other cloud-based application that has ever been built, we suffered our share of downtime and application performance problems as a result of unforeseen circumstances.
As the years went by and our support teams changed hands, the process (or lack thereof) changed as well. The amount of time we provided notice before scheduled maintenance events was never set in stone. The language used within unexpected system outages rarely found the right balance between providing the customers too much or too little information. And to top it off, no matter what we did, nothing seemed to reduce the number of irate customers calling our help desk, even if we gave them weeks of advance notice.
Lessons Learned
-
Overstressed help desks. When applications become unavailable, the natural response of its users are to reach out and find what’s wrong. Any application with more than a handful of users is going to quickly inundate your help desk team with inbound support requests. The expense of having your help desk respond to each of these requests with (hopefully) the same message over and over again, should not be overlooked.
-
Lost employee productivity – Frustrated and idle employees are a nightmare and costly. The Aberdeen Group’s estimates an average size company loses $110,000 an hour when an application becomes unavailable. Your goal as someone managing downtime should be to make those times frictionless for your users. This means having a process in place that proactively keeps your users in the know so they can be as efficient as possible. If you sell a SaaS, frustrated customers don’t translate to lost employee productivity, they translate to ex-customers.
Going Forward
-
Create a culture of communication. It should be hardwired into your team’s DNA: when something goes wrong, before we even start looking at the problem, let the customers know.
- Create multiple channels for customers to find out what’s going on. Don’t expect every customer to be sitting at their desk reading e-mails, or browsing their Twitter feed.
- Decide on your level of transparency up front. Employees need to feel empowered to communicate with their customers without having to worry about backlash from their manager. Clear guidelines as to what words should and shouldn’t be used are important. Does your company want to communicate in broad stroke terminology, such as “We are currently experiencing a problem”, or do you want to let your customers know exactly what’s going on “Hard drive B in our Meta Cluster is reporting a bad sector”.
- Decide on your tone. Is uptime communication to your customers and application users going to be used as an opportunity to build brand and relationships? If so, your uptime messages should take a friendlier tone. Is the success of your user base tightly bound to your application uptime? If so, communicating thorough details in stark black-and-white may be more appropriate.
- Keep a record. Stop relying on uptime monitoring services to determine your SLA. We’d be willing to bet that every month your manager is filtering through your uptime reports tweaking the final output used in determining an actual SLA report.
Jasen Fici
Co-founder, Uptime.ly